

The Old Guitarist 1903-1904 Pablo Picasso
EDIT: I started working on a draft of a preprint for this which you can find in the publication and awards section.
I recently got interested in decision theory in the Bayesian context after reading Statistical Decision Theory and Bayesian Analysis by Jim Berger; along with one of my advisors in graduate school having done some work in the area. However I noticed that the majority of the literature focuses on parametric models, and I think there’s a lot of interesting potential to play around with decision theory in nonparametric models; particularly, Gaussian processes. When I started thinking about this I quickly browsed through Google Scholar to see if anything had been done, and found a couple things scattered in the Statistics and Operations Research Literature. That said, I didn’t find anything in the vein of what I was looking to work on, so I believe (to the best of my knowledge) that it’s a novel approach that hopefully people find interesting.
One of the immediate questions that pops up when considering decision theory in any context is “what loss function should we use?” Considering Gaussian process models, you start to get into the space of functional analysis or differential equations. That said, we’ll probably end up using inner products on Hilbert spaces and ODE’s in this blog post, as well as some preliminary stuff on Gaussian processes.
Preliminary Stuff on Gaussian Processes and Reproducing Kernel Hilbert Spaces
A Gaussian process is a stochastic process which serves as a distribution over function spaces. It’s commonly used in Bayesian analysis as a prior on spaces of functions. The defining characteristic of a Gaussian process is that for any finite collection of elements in the support of the random functions, the joint distribution of the function values over the finite set is multivariate Gaussian. We’ll denote that a function is distributed according to a Gaussian process by writing 


The covariance function of a function valued random process is a function taking two values in the domain of. the random functions, and returning the covariance between them:
![\textrm{Cov}_f (u,t) = \int_f (f(u) - \mu (u) ) (f(t)- \mu (t) ) d\mathbb{P}_f = E_{\mathbb{P}_f}[(f(u) - \mu (u) ) (f(t)- \mu (t) )]](https://s0.wp.com/latex.php?latex=%5Ctextrm%7BCov%7D_f+%28u%2Ct%29+%3D+%5Cint_f+%28f%28u%29+-+%5Cmu+%28u%29+%29+%28f%28t%29-+%5Cmu+%28t%29+%29+d%5Cmathbb%7BP%7D_f+%3D+E_%7B%5Cmathbb%7BP%7D_f%7D%5B%28f%28u%29+-+%5Cmu+%28u%29+%29+%28f%28t%29-+%5Cmu+%28t%29+%29%5D&bg=ffffff&fg=000&s=0&c=20201002)
Where 
For the sake of simplicity from here on out we’re considering mean standardized gaussian processes, so 

![\textrm{Cov}_f(u,t) = E_{\mathbb{P}_f}[f(u)f(t)]](https://s0.wp.com/latex.php?latex=%5Ctextrm%7BCov%7D_f%28u%2Ct%29+%3D+E_%7B%5Cmathbb%7BP%7D_f%7D%5Bf%28u%29f%28t%29%5D&bg=ffffff&fg=000&s=0&c=20201002)
To get back to the point of the Gaussian process example we need to briefly explain what a reproducing kernel Hilbert space is. Looking at our Hilbert space 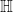



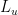





Importantly because 






The Moore-Aronszajn theorem says that if 
Now to ground this a bit and bring it back to the Gaussian process defined above: looking at our Gaussian process measure 
![\textrm{Cov}_f(u,t) = \mathbb{E}_{\mathbb{P}_f}[f(u)f(t)]](https://s0.wp.com/latex.php?latex=%5Ctextrm%7BCov%7D_f%28u%2Ct%29+%3D+%5Cmathbb%7BE%7D_%7B%5Cmathbb%7BP%7D_f%7D%5Bf%28u%29f%28t%29%5D&bg=ffffff&fg=000&s=0&c=20201002)
Switching It around a bit, suppose we start with a kernel 

![\textrm{Cov}_{\mathbb{P}_f} (u,t) = K(u,t) = E_{\mathbb{P}_f}[f(u)f(t)] = <K_u,K_t>_{\mathbb{H}_K}](https://s0.wp.com/latex.php?latex=%5Ctextrm%7BCov%7D_%7B%5Cmathbb%7BP%7D_f%7D+%28u%2Ct%29+%3D+K%28u%2Ct%29+%3D+E_%7B%5Cmathbb%7BP%7D_f%7D%5Bf%28u%29f%28t%29%5D+%3D+%3CK_u%2CK_t%3E_%7B%5Cmathbb%7BH%7D_K%7D&bg=ffffff&fg=000&s=0&c=20201002)
Where 
This is how most people typically work with Gaussian processes in applied settings. They start with a kernel, and this kernel defines a covariance function on a RKHS implied by the kernel, and this covariance function dictates the properties of the random functions realized from the Gaussian process.
Background for Bayesian Updating for GPs and Derivative Function of a GP
We can evaluate the covariance of the random process at a variety of different locations by taking the outer product of the functions at a number of locations:
![\textrm{Cov}_f(\textbf{u}) = E_{\mathbb{P}_f}[f(\textbf{u})f(\textbf{u})^T] = E_{\mathbb{P}_f}[[f(u_1),...,f_{|\textbf{u}|}][[f(u_1),...,f_{|\textbf{u}|}]^T] = K(\textbf{u},\textbf{u})](https://s0.wp.com/latex.php?latex=%5Ctextrm%7BCov%7D_f%28%5Ctextbf%7Bu%7D%29+%3D+E_%7B%5Cmathbb%7BP%7D_f%7D%5Bf%28%5Ctextbf%7Bu%7D%29f%28%5Ctextbf%7Bu%7D%29%5ET%5D+%3D+E_%7B%5Cmathbb%7BP%7D_f%7D%5B%5Bf%28u_1%29%2C...%2Cf_%7B%7C%5Ctextbf%7Bu%7D%7C%7D%5D%5B%5Bf%28u_1%29%2C...%2Cf_%7B%7C%5Ctextbf%7Bu%7D%7C%7D%5D%5ET%5D+%3D+K%28%5Ctextbf%7Bu%7D%2C%5Ctextbf%7Bu%7D%29&bg=ffffff&fg=000&s=0&c=20201002)
Where 
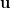


Noting that the definition of a Gaussian process is marginal normality, the Gaussian processs evaluated at the points

The multivariate normal has a convenient conditioning property involving the Schur-complement, so if we set up the follow Bayesian hierarchical nonparametric model:


and we observe 




Where 


Similarly, given a Gaussian process 




However, evaluating the derivative function as it correlates to a value of the original random function is another matter. In this context, if one wants to realize a random function and realize a derivative for that same random function one needs to take the partial derivative with respect to only one of the arguments of the covariance function. So 



The correlation between 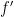


A realization from this multivariate Gaussian will contain realizations for 
Bayesian Decision Theory for Gaussian Processes with an Application to Ordinary Differential Equations (ODEs)
Decision theory is the science of making decisions in uncertain settings with some notion of loss or utility involved. Typically for parameter in a Bayesian model, 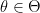





The Bayes decision 
![\delta^* = \min_{\delta \in \Delta}E_{P_{\theta | X}}[L(\delta, \theta)]](https://s0.wp.com/latex.php?latex=%5Cdelta%5E%2A+%3D+%5Cmin_%7B%5Cdelta+%5Cin+%5CDelta%7DE_%7BP_%7B%5Ctheta+%7C+X%7D%7D%5BL%28%5Cdelta%2C+%5Ctheta%29%5D&bg=ffffff&fg=000&s=0&c=20201002)
So how is this relevant to differential equations? Well, our Gaussian process is a distribution over functions, so if we encode the boundary conditions for the various derivatives in the differential equations as our observed data
To clarify what I mean by this, assuming the Gaussian process is the solution to an ODE, we can minimize the loss with respect to the source function as our decision, to evaluate a source function that generated the Gaussian process as a solution to the differential equation.
That is, if the Gaussian process fixed with the boundary condition as it’s observation is a random function, and that function is the solution to some ODE with some source function, then taking the posterior expected loss of a loss function which measures the difference between the GP and different source functions minimizes the long term risk of assuming that source function generated the GP as a solution to a differential equation involving that source.
For the sake of clarity we consider a simple first order linear ODE: 



Then a loss that makes sense for this goal would be the 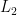


Taking the posterior expected loss we get:
![E_{y,y' | y(u^*) = C}[\int_{u}(y^{(1)}(u) + P(u)y(u) - Q(u))^2du]](https://s0.wp.com/latex.php?latex=E_%7By%2Cy%27+%7C+y%28u%5E%2A%29+%3D+C%7D%5B%5Cint_%7Bu%7D%28y%5E%7B%281%29%7D%28u%29+%2B+P%28u%29y%28u%29+-+Q%28u%29%29%5E2du%5D&bg=ffffff&fg=000&s=0&c=20201002)
Under the assumptions of Fubini’s Theorem (which are going to be situation dependent), we can exchange the integration and expectation to give us:
![\int_u E_{y,y' | y(u^*) = C}[(y^{(1)}(u) + P(u)y(u) - Q(u))^2] du](https://s0.wp.com/latex.php?latex=%5Cint_u+E_%7By%2Cy%27+%7C+y%28u%5E%2A%29+%3D+C%7D%5B%28y%5E%7B%281%29%7D%28u%29+%2B+P%28u%29y%28u%29+-+Q%28u%29%29%5E2%5D+du&bg=ffffff&fg=000&s=0&c=20201002)
Then our goal is to minimize this loss. This is where the “point wise” interpretation comes in.
Recall that joint distribution of 
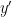

But we have observed 



Then, reducing the previous integral over
![\sum_{u \in \textbf{u}} E_{y,y' | y(u^*) = C}[(y^{(1)}(u) + P(u)y(u) - Q(u))^2]](https://s0.wp.com/latex.php?latex=%5Csum_%7Bu+%5Cin+%5Ctextbf%7Bu%7D%7D+E_%7By%2Cy%27+%7C+y%28u%5E%2A%29+%3D+C%7D%5B%28y%5E%7B%281%29%7D%28u%29+%2B+P%28u%29y%28u%29+-+Q%28u%29%29%5E2%5D&bg=ffffff&fg=000&s=0&c=20201002)
Where our decision where we are trying to minimize this loss is the decision ![\delta^* = \min_{\textbf{Q(u)}} \sum_{u \in \textbf{u}} E_{y,y' | y(u^*) = C}[(y^{(1)}(u) + P(u)y(u) - Q(u))^2]](https://s0.wp.com/latex.php?latex=%5Cdelta%5E%2A+%3D+%5Cmin_%7B%5Ctextbf%7BQ%28u%29%7D%7D+%5Csum_%7Bu+%5Cin+%5Ctextbf%7Bu%7D%7D+E_%7By%2Cy%27+%7C+y%28u%5E%2A%29+%3D+C%7D%5B%28y%5E%7B%281%29%7D%28u%29+%2B+P%28u%29y%28u%29+-+Q%28u%29%29%5E2%5D&bg=ffffff&fg=000&s=0&c=20201002)
Note that the expectation above is a second order polynomial expectation of 
![E_{y,y' | y(u^*) = C}[(y^{(1)}(u) + P(u)y(u) - Q(u))^2] = E[(AY-Q)^2]](https://s0.wp.com/latex.php?latex=E_%7By%2Cy%27+%7C+y%28u%5E%2A%29+%3D+C%7D%5B%28y%5E%7B%281%29%7D%28u%29+%2B+P%28u%29y%28u%29+-+Q%28u%29%29%5E2%5D+%3D+E%5B%28AY-Q%29%5E2%5D&bg=ffffff&fg=000&s=0&c=20201002)
![A^T = [P(u_1),...,P(u_n),\underbar{1}_n]](https://s0.wp.com/latex.php?latex=A%5ET+%3D+%5BP%28u_1%29%2C...%2CP%28u_n%29%2C%5Cunderbar%7B1%7D_n%5D&bg=ffffff&fg=000&s=0&c=20201002)
![\sum_{u\in\textbf{u}} E_{y,y' | y(u^*) = C}[(AY-Q)^2] = \sum_{u\in\textbf{u}} E_{y,y' | y(u^*) = C}[AYAY - AYQ - QAY + Q\circ Q]](https://s0.wp.com/latex.php?latex=%5Csum_%7Bu%5Cin%5Ctextbf%7Bu%7D%7D+E_%7By%2Cy%27+%7C+y%28u%5E%2A%29+%3D+C%7D%5B%28AY-Q%29%5E2%5D+%3D+%5Csum_%7Bu%5Cin%5Ctextbf%7Bu%7D%7D+E_%7By%2Cy%27+%7C+y%28u%5E%2A%29+%3D+C%7D%5BAYAY+-+AYQ+-+QAY+%2B+Q%5Ccirc+Q%5D+&bg=ffffff&fg=000&s=0&c=20201002)
![= \sum_{u\in\textbf{u}}[AE_{y,y' | y(u^*) = C}[YAY] - AE_{y,y' | y(u^*) = C}[Y]Q - QE_{y,y' | y(u^*) = C}[Y]A + Q\circ Q]](https://s0.wp.com/latex.php?latex=%3D+%5Csum_%7Bu%5Cin%5Ctextbf%7Bu%7D%7D%5BAE_%7By%2Cy%27+%7C+y%28u%5E%2A%29+%3D+C%7D%5BYAY%5D+-+AE_%7By%2Cy%27+%7C+y%28u%5E%2A%29+%3D+C%7D%5BY%5DQ+-+QE_%7By%2Cy%27+%7C+y%28u%5E%2A%29+%3D+C%7D%5BY%5DA+%2B+Q%5Ccirc+Q%5D&bg=ffffff&fg=000&s=0&c=20201002)
Which by properties of expectations of quadratic forms has expectation:

Which can be minimized to find the source function values 
Conclusion
A lot of this is probably overkill for such a simple differential equation, but I just wanted to show this could be done. Some interesting things to consider are if this can be used to show or enforce smoothness properties on differential equations of higher order, or for partial differential equations. Additionally, the number of boundary conditions does not matter in this context, and other loss and utility functions could be used. Restrictions of GPs to other locations is also valid, and one could even use all observed values of a GP process as boundary conditions (more than one boundary condition for this ODE would not create any difficulties).
One thing I wanted to consider when working on this was financial applications; where differential equations and stochastic processes are prominent. Another thing to consider is that a Gaussian process is a convenient approximation to other stochastic processes, or deep learning models. I’m also curious about using decision theory for Dirichlet process models, and what kind of loss / utility functions would fit well in that space. In the Dirichlet process mixture setting it might open up some possibilities to properly assign subjects to clusters given some sense of costs or rewards.
If you stuck with it this far I appreciate it, and hopefully the write up made sense. Thanks for checking out my blog :).
Leave a Reply