

Disclaimer: This blog post is a work in progress, but I wanted to share here in case anyone had any thoughts on it.
It had been a while since I had done any personal pet technical projects on my blog, but I had an interesting realization while playing around with Principal Components Analysis (PCA) on another project, and wanted to do something related to that in the context of Bayesian nonparametric.
I had an intuition on something related to projections on dirichlet process distributed random vectors, and I was curious if there was a way to do a kind of nonparametric projection onto an infinite-dimensional space that would be useful for certain high-dimensional or infinite-dimensional dimension reduction problems, so I decided I would delve into it. I’m also trying to get familiar with the new GitHub copilot tool on VSCode, so, unlike my other blog posts, I have a computational component to this that you can find here with a notebook illustrating the approach.
My first thought about this was to see if I could come up with a simple model built around the Dirichlet process and see if some interesting conjugacy results would fall out. At first pass the most obvious model specification was something to the effect of the following:






The only difference here from a mathematical perspective from the normal dirichlet process mixture of normals is that the data are not univariate but we are projecting onto a univariate distribution with support on a one dimensional subspace of 

So it appears that if we want to preserve the Dirichlet process as a feature of the model, then we need to find a way to incorporate the necessary orthogonality into the top level of the hierarchy. This means that we need to modify the 
One way to do this is to construct a varying dimension hierarchy, where each level of the hierarchy going down removes the projection of the current vector on the span of all previous ones. Expressing this mathematically we have a random 


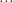

Forgive me for the poor formatting due to the limited space on the blog page :).
I think looking at this hierarchy there is some natural confusion (for me at least initially) about what this means in the context of a hierarchical model. Think of this hierarchy as a joint distribution on the 
Theorem 1: The joint distribution defined by the hierarchical projections onto orthogonal random vectors is well defined and non-atomic.
Proof: This proof will be a tad bit informal for the sake of illustration. We need to show that 



is a well defined joint model. There’s also the possibility of some identifiability coming from the hierarchical structure of the joint model which we will get into in another theorem later
The first step is that the first two distributions define a joint model on 

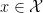


We now proceed by induction on 



If 


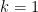

That is to say. For any fixed
There is one additional thing we’re interested in along the same lines, and that is what happens concerning 



This gives us the following model:



I want to note something else here with another theorem now that the model has been more fleshed out:
Theorem 2: The distribution above on 


where ![G = [g_1^T,....,(g_{K_G} - \textrm{proj}(g_{K_G}\rightarrow \textrm{span}(g_1,...,g_{K_G-1}))^T]](https://s0.wp.com/latex.php?latex=G+%3D+%5Bg_1%5ET%2C....%2C%28g_%7BK_G%7D+-+%5Ctextrm%7Bproj%7D%28g_%7BK_G%7D%5Crightarrow+%5Ctextrm%7Bspan%7D%28g_1%2C...%2Cg_%7BK_G-1%7D%29%29%5ET%5D&bg=ffffff&fg=000&s=0&c=20201002)


This is essentially saying if we condition on 






Proof:
……….
Markov Chain Monte Carlo Algorithm (MCMC):
People familiar with more advanced Bayesian computation can probably see that the algorithm to sample from the posterior (which is not available in closed form) is likely to be a Metropolis-Hastings-Green within Gibbs algorithm. The Metropolitan-Hastings-Green comes from the dimension changing. It will be interesting to see if there is any types of conjugacy or mathematical properties of the Green algorithm as well as the full conditionals for the Gibbs component.
We split 

- We have that
which is also the same as saying that
projecting the data
onto
we get that
are our observations and our likelihood is a normal with mean zero and unknown precision. This is conjugate and we get that:
- For the directional component of
(which are orthonormal vectors) we have that
is an element of the Stiefel manifold on orthonormal p-frames. Thus the distribution on the projected vectors
with A fixed to the identity. This gives us one parameter to control over our prior,
:
where
is
- Using cyclical properties of traces and their additivity this gives us:
- Note that because
giving us:
.
- The
is a constant term which factors out, giving us that our full conditional is:
.
- This means the posterior is invariant under the parameter
which is the same as our isometric normal projections (or uniform on the
Steifel manifold.



Note that both of these full conditionals are invariant under the choice of
Sampling from Bingham distributions is challenging so here I propose a new sampler built on the orthogonal projections.
Sample ![G \sim \textrm{MN}(0, ||G||^{-1}, 2(XX^T)^{-1}) \propto \exp[-\textrm{tr}(XX^TG^T||G||G)]](https://s0.wp.com/latex.php?latex=G+%5Csim+%5Ctextrm%7BMN%7D%280%2C+%7C%7CG%7C%7C%5E%7B-1%7D%2C+2%28XX%5ET%29%5E%7B-1%7D%29+%5Cpropto+%5Cexp%5B-%5Ctextrm%7Btr%7D%28XX%5ETG%5ET%7C%7CG%7C%7CG%29%5D&bg=ffffff&fg=000&s=0&c=20201002)



![\propto \exp[\textrm{tr}(XX^TG^T||G||G)]](https://s0.wp.com/latex.php?latex=%5Cpropto+%5Cexp%5B%5Ctextrm%7Btr%7D%28XX%5ETG%5ET%7C%7CG%7C%7CG%29%5D&bg=ffffff&fg=000&s=0&c=20201002)
Function Spaces:
As mentioned previously the goal was to use the same hierarchical projection structure on a distribution over functions with a DP as the mixing measure; as opposed to the Dirichlet distribution on the ordinal numbers




Leave a Reply