
I recently worked on an applied project involving Mixture Density Networks (MDNs), and it got me pondering them more from the statistical perspective. Most of the papers on MDNs are based around computational approaches or application. I also haven’t actually used this blog for any blog posts, so I wanted to get something out there and maybe start a pattern of contributing more regularly.
MDNs were proposed by Christopher Bishop in a 1994 technical report, and they have gained traction recently as a number of modern software packages became capable of efficiently implementing them. tensorflow/tensorflow-probability and pytorch/pyro are two examples of package pairs where the shared infrastructure allows welding together of probabilistic elements with neural networks and algorithmic differentiation in a cohesive fashion, and using these tools permits relatively easy implementation of the MDN concept. A quick Google Scholar search yields many results on applications of MDNs in problems ranging from climate science to robotics.
The basic concept of a MDN is that, instead of using of using a neural network to deterministically predict the output, you use the network to predict the parameters of a distribution over the output, and then maximize the likelihood of the weights of the network with respect to the distribution over the data. That is, instead of estimating the weights of the network in an attempt to estimate the function 





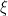


The way inference is typically done is to maximize the log likelihood as a function of the weights of the network. That is, for any network architecture with weights 



Where 

Let 


where 
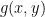


![\hat{\eta} = \textrm{argmin}_\eta -\frac{1}{n}\sum_{i=1}^n \log[f_\eta(y_i| x_i)]](https://s0.wp.com/latex.php?latex=%5Chat%7B%5Ceta%7D+%3D+%5Ctextrm%7Bargmin%7D_%5Ceta+-%5Cfrac%7B1%7D%7Bn%7D%5Csum_%7Bi%3D1%7D%5En+%5Clog%5Bf_%5Ceta%28y_i%7C+x_i%29%5D&bg=ffffff&fg=000&s=0&c=20201002)
The Law of Large Numbers gives us that, as 
![\hat{\eta} \overset{P}{\rightarrow} \textrm{argmin}_\eta -\textrm{E}_G[\log[f_\eta(Y|X)]]](https://s0.wp.com/latex.php?latex=%5Chat%7B%5Ceta%7D+%5Coverset%7BP%7D%7B%5Crightarrow%7D++%5Ctextrm%7Bargmin%7D_%5Ceta+-%5Ctextrm%7BE%7D_G%5B%5Clog%5Bf_%5Ceta%28Y%7CX%29%5D%5D&bg=ffffff&fg=000&s=0&c=20201002)
We also have that, because 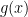
![\textrm{E}_G[g(X)]](https://s0.wp.com/latex.php?latex=%5Ctextrm%7BE%7D_G%5Bg%28X%29%5D&bg=ffffff&fg=000&s=0&c=20201002)
![\hat{\eta} \overset{P}{\rightarrow} \textrm{argmin}_\eta -\textrm{E}_G[\log[f_\eta(Y|X)g(X)]]](https://s0.wp.com/latex.php?latex=%5Chat%7B%5Ceta%7D+%5Coverset%7BP%7D%7B%5Crightarrow%7D+%5Ctextrm%7Bargmin%7D_%5Ceta+-%5Ctextrm%7BE%7D_G%5B%5Clog%5Bf_%5Ceta%28Y%7CX%29g%28X%29%5D%5D&bg=ffffff&fg=000&s=0&c=20201002)
Now note that ![\textrm{E}_G[\log[g(Y|X)g(X)]]](https://s0.wp.com/latex.php?latex=%5Ctextrm%7BE%7D_G%5B%5Clog%5Bg%28Y%7CX%29g%28X%29%5D%5D&bg=ffffff&fg=000&s=0&c=20201002)
![\hat{\eta} \overset{P}{\rightarrow} \textrm{argmin}_\eta -\textrm{E}_G[\log[f_\eta(Y|X)g(X)]] + \textrm{E}_G[\log[g(Y|X)g(X)]]](https://s0.wp.com/latex.php?latex=%5Chat%7B%5Ceta%7D+%5Coverset%7BP%7D%7B%5Crightarrow%7D++%5Ctextrm%7Bargmin%7D_%5Ceta+-%5Ctextrm%7BE%7D_G%5B%5Clog%5Bf_%5Ceta%28Y%7CX%29g%28X%29%5D%5D+%2B+%5Ctextrm%7BE%7D_G%5B%5Clog%5Bg%28Y%7CX%29g%28X%29%5D%5D&bg=ffffff&fg=000&s=0&c=20201002)
Rearranging a bit by putting the two logs together, and using the fact that 
![\hat{\eta} \overset{P}{\rightarrow} \textrm{argmin}_\eta -\textrm{E}_G[\log[\frac{f_\eta(Y|X)g(X)}{g(X,Y)}]]](https://s0.wp.com/latex.php?latex=%5Chat%7B%5Ceta%7D+%5Coverset%7BP%7D%7B%5Crightarrow%7D+%5Ctextrm%7Bargmin%7D_%5Ceta+-%5Ctextrm%7BE%7D_G%5B%5Clog%5B%5Cfrac%7Bf_%5Ceta%28Y%7CX%29g%28X%29%7D%7Bg%28X%2CY%29%7D%5D%5D&bg=ffffff&fg=000&s=0&c=20201002)
Which is the Kullback-Leibler Divergence between 


Breaking this apart a little bit, note that if the family 
![\textrm{P}[F_{\hat{\eta}}(A) = G(A)]=1](https://s0.wp.com/latex.php?latex=%5Ctextrm%7BP%7D%5BF_%7B%5Chat%7B%5Ceta%7D%7D%28A%29+%3D+G%28A%29%5D%3D1&bg=ffffff&fg=000&s=0&c=20201002)




Noting that we can remove the
![\hat{\eta} \overset{P}{\rightarrow} \textrm{argmin}_\eta -\textrm{E}_G[\log[\frac{f_\eta(Y|X)}{g(Y|X)}]]](https://s0.wp.com/latex.php?latex=%5Chat%7B%5Ceta%7D+%5Coverset%7BP%7D%7B%5Crightarrow%7D+%5Ctextrm%7Bargmin%7D_%5Ceta+-%5Ctextrm%7BE%7D_G%5B%5Clog%5B%5Cfrac%7Bf_%5Ceta%28Y%7CX%29%7D%7Bg%28Y%7CX%29%7D%5D%5D&bg=ffffff&fg=000&s=0&c=20201002)
Using properties of conditional expectations we get:
![\hat{\eta} \overset{P}{\rightarrow} \textrm{argmin}_\eta \textrm{E}_{G_X}[-\textrm{E}_{G_{Y|X}}[\log[\frac{f_\eta(Y|X)}{g(Y|X)}]| X]]](https://s0.wp.com/latex.php?latex=%5Chat%7B%5Ceta%7D+%5Coverset%7BP%7D%7B%5Crightarrow%7D+%5Ctextrm%7Bargmin%7D_%5Ceta+%5Ctextrm%7BE%7D_%7BG_X%7D%5B-%5Ctextrm%7BE%7D_%7BG_%7BY%7CX%7D%7D%5B%5Clog%5B%5Cfrac%7Bf_%5Ceta%28Y%7CX%29%7D%7Bg%28Y%7CX%29%7D%5D%7C+X%5D%5D&bg=ffffff&fg=000&s=0&c=20201002)
So the term inside is the KL divergence between the distribution with density 

There are some problems with the calculations done previously, mainly some identifiability assumptions. The previous outline is mostly following along inline with Theorem 2.1 and 2.2 of a 1982 paper by Halbert White titled Maximum Likelihood Estimation in Misspecified Models in Econometrica. The primary assumptions we need are from A3 in that paper:
-
needs to exist and
for every
where
is integrable with respect to
has a unique minimum in
- To incorporate the fact that the results in the previously referenced paper didn’t have the conditional distribution component, we also need the assumption that
exists.
The assumptions on
There’s also some possibilities of calculating the asymptotic distributions of the weights given some additional assumptions outlined in the previously referenced paper. Most of the results should still apply with some additional requirements; as we’re approximating the conditional distribution using the MDN and not the full joint distribution of the data
I was really interested in MDNs when I first heard about them. I think analyzing them from this perspective gives insight into how to build models with desirable asymptotic properties, and even the entropy assumptions on
Thanks to Anar Yusifov for introducing me to MDNs, and for many insightful discussions on the topic.
Leave a Reply