I’ve previously worked on applications of Bayesian inversion to inverse problems in geophysics. I wanted to talk a little bit about Bayesian inversion and analyze it from a theoretical perspective; as well as give an illustration.
Bayesian inversion is a method for finding solutions to inverse problems using the machinery of Bayesian statistics. By nature probabilistic, it has some advantages over deterministic methods. It seems like geophysics is a place where this approach towards solving inverse problems has become adopted more readily, but it’s likely that it could be applied to other domains as well.
The main idea behind Bayesian inverse methods is that you have a function  , where
, where  and
and  and
and  are two Lebesgue measurable measure spaces; maybe
are two Lebesgue measurable measure spaces; maybe 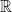 or
or  for some
for some  with the standard Borel
with the standard Borel  algebra. You observe some
algebra. You observe some  and want to invert
and want to invert  to obtain
to obtain  such that
such that  .
.

The reason the probabilistic approach, and Bayesian methods included, is useful is that could be ill posed; being a many to one mapping. This means that there is a set of solutions to the inverse problem which all map to  . Additionally, some solutions might approximately map to , but not exactly, meaning that uncertainty around which solutions solve the inverse problem exists.
. Additionally, some solutions might approximately map to , but not exactly, meaning that uncertainty around which solutions solve the inverse problem exists.
The Bayesian approach sets the problem up in a Bayesian fashion. If we have a likelihood,  , and a prior,
, and a prior,  , we can use Bayes’ theorem to get a distribution over possible solutions to the problem:
, we can use Bayes’ theorem to get a distribution over possible solutions to the problem:

This solution might be difficult to analytically express due to the intractability of the integral  , but there’s nothing distinguishing the problem at this point from a typical Bayesian problem, and things like variational inference, Markov chain Monte Carlo, or Stein Variational Gradient Descent could be used to achieve the posterior.
, but there’s nothing distinguishing the problem at this point from a typical Bayesian problem, and things like variational inference, Markov chain Monte Carlo, or Stein Variational Gradient Descent could be used to achieve the posterior.
My main interest in writing this blog post was on the accuracy of the approximation, and ways in which it can be tweaked or modified. For example, say  , and we place
, and we place  , and
, and  . Obviously
. Obviously 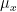 and
and  affect the posterior distribution in the way they might in a conventional Bayesian framework, but what about
affect the posterior distribution in the way they might in a conventional Bayesian framework, but what about  ?
?
Another thing to consider is the observation . We have only one observation, which is not very informative, but we know that the problem is set up in such a way that we can have as many of this observation as we want; this is because this is the solution to the problem. So we get  . Then we have that the likelihood is
. Then we have that the likelihood is  . If we do things in this way, our posterior is given by:
. If we do things in this way, our posterior is given by:

So we have four parameters to control: , , , and  , and these parameters affect our posterior.
, and these parameters affect our posterior.
Suppose that 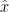 is the singular solution to the problem, and that we have that
is the singular solution to the problem, and that we have that  is sufficiently close to (so that
is sufficiently close to (so that  is approximately constant). Then as
is approximately constant). Then as  , and under some regularity assumptions, we have:
, and under some regularity assumptions, we have:
![P(x|y) \approx \frac{\exp[\log P(y|\hat{x}) - \frac{1}{2} (x - \hat{x})^T\hat{I}_n(\hat{x})(x - \hat{x})]P(\hat{x})}{\int_\mathbb{X} \exp[\log P(y|\hat{x}) - \frac{1}{2} (x - \hat{x})^T\hat{I}_n(\hat{x})(x - \hat{x})]P(\hat{x}) dx}](https://s0.wp.com/latex.php?latex=P%28x%7Cy%29+%5Capprox+%5Cfrac%7B%5Cexp%5B%5Clog+P%28y%7C%5Chat%7Bx%7D%29+-+%5Cfrac%7B1%7D%7B2%7D+%28x+-+%5Chat%7Bx%7D%29%5ET%5Chat%7BI%7D_n%28%5Chat%7Bx%7D%29%28x+-+%5Chat%7Bx%7D%29%5DP%28%5Chat%7Bx%7D%29%7D%7B%5Cint_%5Cmathbb%7BX%7D+%5Cexp%5B%5Clog+P%28y%7C%5Chat%7Bx%7D%29+-+%5Cfrac%7B1%7D%7B2%7D+%28x+-+%5Chat%7Bx%7D%29%5ET%5Chat%7BI%7D_n%28%5Chat%7Bx%7D%29%28x+-+%5Chat%7Bx%7D%29%5DP%28%5Chat%7Bx%7D%29+dx%7D&bg=ffffff&fg=000&s=0&c=20201002)
Where ![\hat{I}_n(\hat{x}) = -\frac{1}{n} [\frac{\partial^2}{\partial x^{(k)}\partial x^{(l)}}\log \textrm{N}(f(x). \Sigma_y) |_{x = \hat{x}}]_{kl}](https://s0.wp.com/latex.php?latex=%5Chat%7BI%7D_n%28%5Chat%7Bx%7D%29+%3D+-%5Cfrac%7B1%7D%7Bn%7D+%5B%5Cfrac%7B%5Cpartial%5E2%7D%7B%5Cpartial+x%5E%7B%28k%29%7D%5Cpartial+x%5E%7B%28l%29%7D%7D%5Clog+%5Ctextrm%7BN%7D%28f%28x%29.+%5CSigma_y%29+%7C_%7Bx+%3D+%5Chat%7Bx%7D%7D%5D_%7Bkl%7D&bg=ffffff&fg=000&s=0&c=20201002) is the Fisher information matrix.
is the Fisher information matrix.
However note that  for a given
for a given 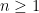 just scales for
just scales for 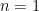 and a different value for ; where is scaled by a factor of
and a different value for ; where is scaled by a factor of 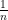 . This means that in actuality the number of repeated observations of the same value for doesn’t matter, it just controls how diffusive the likelihood is; which we already have control over through . So is an erroneous parameter and can be discarded.
. This means that in actuality the number of repeated observations of the same value for doesn’t matter, it just controls how diffusive the likelihood is; which we already have control over through . So is an erroneous parameter and can be discarded.
This gives us that:

In a neighborhood of sufficiently close to ; this contracts as gets less diffuse. This is just a Bernstein Von-Mises theorem controlling the diffusivity of the likelihood directly through the parameter as opposed to increasing the sample size. The book Statistical Decision Theory and Bayesian Analysis by Jim Berger has a good heuristic sketch of the classical Bernstein Von-Mises theorems, and I used that book as a reference here.
Now consider

Where  denotes the Mahalanobis distance and
denotes the Mahalanobis distance and  is chosen such that
is chosen such that 
 satisfying the previous inequality.
satisfying the previous inequality.

This gives us some intuition about the role and play in the problem, they define what the notion of “closeness” means in terms of the two different aspects of the solution. If under the elliptical geometry of is close to (or  since
since  ), then, under the geometry of , being close to
), then, under the geometry of , being close to
 gives us the notion of “sufficiently close” that was talked about previously with the normality result.
gives us the notion of “sufficiently close” that was talked about previously with the normality result.
Understanding what these parameters mean has values in terms of setting up the machinery of the problem. Typically in Bayesian inversion people just assume isometric normality for the prior and likelihood, but if there’s structural information about the inverse problem that can be framed in terms of these parameters it might be beneficial to do so.

Leave a Reply