

Edit: This blog post has been developed into a preprint and extended in a number of ways. You can view the preprint on my ResearchGate here.
I was introduced to the concept of aleatoric uncertainty in the context of Bayesian neural networks, but I was recently working on a project for outlier detection and got interested in how reframing approaches from decision theory to a version of aleatoric uncertainty for typical Bayesian models could provide a mechanism for outlier detection. I also want to thank Karl Hallgren for inspiring me to think more about Bayesian outlier dection.
The reason this comes up naturally in the Bayesian context is because the model has some inherent uncertainty. Thinking of a parametric model, acknowledging in the Bayesian paradigm our uncertainty in the parameters we get that a distribution over the parameters maps to a distribution over a finite dimensional subspace of all distributions on the data. Thus the two types of uncertainty: our uncertainty in the model, epistemic, and our uncertainty in the data generating mechanism, aleatoric.
Introduction:
To see why this is useful for large scale outlier detection let us analyze a simple model. Suppose the data are assumed to follow 




These parameters are fairly complicated, so denote the parameters 

Referring to the point made previously, we have a distribution over 
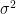



which luckily for this simple model has a closed form solution:

Where the distribution is a non-centered student-t distribution, with 


Where Decision Theory Comes In:
Where this idea of uncertainty in the data being inherited from the model uncertainty becomes useful is in outlier detection. Say we observe an observation 

Now to incorporate some ideas from decision theory, suppose we observed 







Where 

This loss function provides an incentive for true positives in the first addendum, 


In typical decision theory we use the posterior expected loss and minimize it, but in this context we’re working with aleatoric uncertainty; so we take the posterior predictive expected loss. This gives us:
![\mathbb{E}_{X|X_1,...,X_n}[L(X^*, X)] = - \sum_{j=1}^m \delta_j P(X^*_{(n+1)j} > X_{(n+1)j} | X_{1j},...,X_{nj}) + c_1\sum_{j=1}^m (1-\delta_j) P(X^*_{(n+1)j} > X_{(n+1)j} | X_{1j},...,X_{nj}) + c_2D](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D_%7BX%7CX_1%2C...%2CX_n%7D%5BL%28X%5E%2A%2C+X%29%5D+%3D+-+%5Csum_%7Bj%3D1%7D%5Em+%5Cdelta_j+P%28X%5E%2A_%7B%28n%2B1%29j%7D+%3E+X_%7B%28n%2B1%29j%7D+%7C+X_%7B1j%7D%2C...%2CX_%7Bnj%7D%29+%2B+c_1%5Csum_%7Bj%3D1%7D%5Em+%281-%5Cdelta_j%29+P%28X%5E%2A_%7B%28n%2B1%29j%7D+%3E+X_%7B%28n%2B1%29j%7D+%7C+X_%7B1j%7D%2C...%2CX_%7Bnj%7D%29+%2B+c_2D&bg=ffffff&fg=000&s=0&c=20201002)
Denoting by 

![\mathbb{E}_{X|X_1,...,X_n}[L(X^*, X)] = -\sum_{j=1}^m \delta_j r_j + c_1\sum_{j=1}^m (1-\delta_j)r_j + c_2D](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D_%7BX%7CX_1%2C...%2CX_n%7D%5BL%28X%5E%2A%2C+X%29%5D+%3D+++++-%5Csum_%7Bj%3D1%7D%5Em+%5Cdelta_j+r_j++%2B+c_1%5Csum_%7Bj%3D1%7D%5Em+%281-%5Cdelta_j%29r_j+%2B+c_2D&bg=ffffff&fg=000&s=0&c=20201002)
For which the solution, minimizing with respect to 

This follows along pretty closely with an outline in Section 4 of the article FDR and Bayesian Multiple Comparison Rules by P. Muller, G. Parmigiani, and K. Rice in Bayesian Statistics 8; just using the posterior predictive to calculate probabilities for outliers from the indicator functions, but with the same lower bound on the minimizer of the expected loss.
Alternative Way to Choose Threshold and Data Informed Loss Function:
This means that the optimal decision for this loss function (indicator functions of outliers) is constructed out of some lower bound on 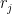
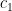
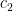



![q\in [0,1]](https://s0.wp.com/latex.php?latex=q%5Cin+%5B0%2C1%5D&bg=ffffff&fg=000&s=0&c=20201002)


This provides a multiplicity control in the correction and offers a less controlled way to manage the false discoveries than tinkering directly with
Let’s now examine, in the context of the previous decision theoretic model, what such a Bayesian FDR dictated threshold means in terms of the values of penalties on multiplicity and false negatives. We set up the following equation and solve for

Rearranging a bit we get:

In other words, the largest such pairing of 


As 
Note that if 





Thus, holding the penalty on false negatives, 


It should be obvious at this point that one can reverse engineer decision criteria to give a loss function for which a particular threshold selection criteria (whatever type, whatever appropriately specified loss function) coincides.
However this is somewhat circular logic, as the Bayesian FDR is necessarily Bayesian, and is taken and evaluated after the expectation is taken. Still I think there’s interesting potential to play around with this generally speaking. Essentially it is saying we have a data dependent loss function. In other words, if you use the the Bayesian FDR a posteriori to select a cutoff, it would have equated to using this decision criteria on that data.
Noting Something Here About Bayesian FDR and the Previous Decision Criteria:
Assume in a typical Bayesian model that we have 





![r_j = E_{\gamma_j | Y}[\gamma_j]](https://s0.wp.com/latex.php?latex=r_j+%3D+E_%7B%5Cgamma_j+%7C+Y%7D%5B%5Cgamma_j%5D&bg=ffffff&fg=000&s=0&c=20201002)
Examine the following loss:

Where 


![E_{\gamma}[FDR^{-1}(q;\gamma)] = BFDR^{-1}(q; r)](https://s0.wp.com/latex.php?latex=E_%7B%5Cgamma%7D%5BFDR%5E%7B-1%7D%28q%3B%5Cgamma%29%5D+%3D+BFDR%5E%7B-1%7D%28q%3B+r%29&bg=ffffff&fg=000&s=0&c=20201002)
Theorem 1:
Statement: For 

![\textrm{E}_{\gamma| Y }[FDR^{-1}(q; \gamma)] = BFDR^{-1}(q; r)](https://s0.wp.com/latex.php?latex=%5Ctextrm%7BE%7D_%7B%5Cgamma%7C+Y+%7D%5BFDR%5E%7B-1%7D%28q%3B+%5Cgamma%29%5D+%3D+BFDR%5E%7B-1%7D%28q%3B+r%29&bg=ffffff&fg=000&s=0&c=20201002)
Proof:
Note that ![\textrm{E}_{\gamma| Y, \eta}[FDR(\eta)] = BFDR(\eta)](https://s0.wp.com/latex.php?latex=%5Ctextrm%7BE%7D_%7B%5Cgamma%7C+Y%2C+%5Ceta%7D%5BFDR%28%5Ceta%29%5D+%3D+BFDR%28%5Ceta%29&bg=ffffff&fg=000&s=0&c=20201002)




![\textrm{E}_{\gamma | Y}[FDR^{-1}(q; \gamma)] = BFDR^{-1}(q; r)](https://s0.wp.com/latex.php?latex=%5Ctextrm%7BE%7D_%7B%5Cgamma+%7C+Y%7D%5BFDR%5E%7B-1%7D%28q%3B+%5Cgamma%29%5D+%3D+BFDR%5E%7B-1%7D%28q%3B+r%29&bg=ffffff&fg=000&s=0&c=20201002)

This gives us that the posterior expectation of our previous loss function I given by:
![\textrm{E}_{\gamma | Y}[L(\omega, \gamma, X)] = - \sum_{j=1}^m \delta_jr_j +c_1\sum_{j=1}^m (1-\delta_j)r_j+BFDR^{-1}(q; r)D](https://s0.wp.com/latex.php?latex=%5Ctextrm%7BE%7D_%7B%5Cgamma+%7C+Y%7D%5BL%28%5Comega%2C+%5Cgamma%2C+X%29%5D+%3D+-+%5Csum_%7Bj%3D1%7D%5Em+%5Cdelta_jr_j+%2Bc_1%5Csum_%7Bj%3D1%7D%5Em+%281-%5Cdelta_j%29r_j%2BBFDR%5E%7B-1%7D%28q%3B+r%29D&bg=ffffff&fg=000&s=0&c=20201002)
Which is a decision criteria with solution:

Additional Note on Bayesian FDR:
We can generalize the Bayesian FDR with the following definition:
Definition:
For 

For 
Illustration:
We have that:

Using the sets outlined 2 sections ago we can see that the previous statement is true.
We note that this expression for 

Note that, ![r_j - q \in [-1,1]](https://s0.wp.com/latex.php?latex=r_j+-+q+%5Cin+%5B-1%2C1%5D&bg=ffffff&fg=000&s=0&c=20201002)
![|r_j - q| \in [0,1]](https://s0.wp.com/latex.php?latex=%7Cr_j+-+q%7C+%5Cin+%5B0%2C1%5D&bg=ffffff&fg=000&s=0&c=20201002)


Note that as 


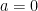


It should be obvious that we can reverse engineer this to get an appropriate 
Another interesting point to consider is that 


Theorem 2:
Let 
![\forall a \geq 0, \hspace{2mm} BDFR(\eta; a) = \textrm{argmin}_{q} \frac{d}{dq}\mathbb{E}_R[|r - q|^{a+1}| R \leq \eta]](https://s0.wp.com/latex.php?latex=%5Cforall+a+%5Cgeq+0%2C+%5Chspace%7B2mm%7D+BDFR%28%5Ceta%3B+a%29+%3D+%5Ctextrm%7Bargmin%7D_%7Bq%7D+%5Cfrac%7Bd%7D%7Bdq%7D%5Cmathbb%7BE%7D_R%5B%7Cr+-+q%7C%5E%7Ba%2B1%7D%7C+R+%5Cleq+%5Ceta%5D&bg=ffffff&fg=000&s=0&c=20201002)
Which is the point which minimizes the change in the
Proof:
The proof follows from applying the dominated convergence theorem to exchange an expectation and a derivative and using laws from basic calculus. There is a 


This theorem also provides us a way to investigate complexities such as those that arise when 
Returning to Outlier Detection in the Scenario of Nonparametric Models:
It’s possible to get more abstract with the posterior predictive expection for outlier detection. For example, suppose we don’t want to use a parametric model, but instead some nonparametric approach. Taking species sampling models as an example, and specifically the Dirichlet process:


We get that the posterior predictive is 


Another important factor to consider is that we used a pretty simple probability event, 
I thought this was an interesting way to look at decision theory, and the loss function can be modified to prioritize different things one might be interested in. Additionally, the flexibility of the approach lends itself to a lot of different applications and generalizations.
Simulations:
I did simulations for both the DP outlier model as well as the NormalInverseGamma outlier model. There are 1000 replicated tests with 750 in the control group and 250 in the “anomalous” group. All data for the control group were simulated according to a 








For the Area under the curve for the outliers for the NormalInverseGamma model we get the following performance

Where the tick marks from left to right, for each individual plot, indicate
Using the Bayesian FDR Threshold and estimating accuracy, precision, and recall, we get the following:

Where the tick marks from left to right, for each individual plot, indicate
Now to examine the DP model, we get the following performance on AUC:

Where the tick marks from left to right, for each individual plot, indicate
For accuracy, precision, and recall, we get the following:

Where the tick marks from left to right, for each individual plot, indicate
The previous plots for accuracy, precision, and recall, for both the DP and NIG, are with 

Leave a Reply