
(EDIT: This work culminated in a research article published here.)
I did some work towards the tail end of graduate school and a little while after during my professional career which was never completed, and never published, on Spatial Dirichlet Process models; as well as convolutions of Spatial Dirichlet Process models with white noise base measure. You can read the notes on the publications page, but the notes were written at a time when I was struggling with some things going on in my personal life, and are generally speaking somewhat erratic and confused. Still, there’s a lot of decent work in there that never got to see the light of day, and I wanted to introduce three theorems from the notes (and fix some issues) here with a better exposition to explain what exactly was going through my mind as the notes were being written.
My technical blog posts lean pretty technical already, but this blog post will use some fairly heavy duty math (at least from my perspective), so I also wanted to give an introduction to things here that could allow people who had not had any familiarity with these concepts to follow and to use it in their own work in other technical settings should they so choose. The primary things of interest are Gaussian processes, Hilbert spaces, compact integral kernel operators between Hilbert spaces and convergent sequences of compact integral kernel operators, the Wasserstein metric on probability measures, the Dirichlet process and it’s associated Sethuraman representation, and a few other bits and pieces here and there that will be outlined in the three main proofs.
A lot of this stuff can be fairly mind bend-y (think distributions over distributions over spatial fields, and measuring distances between them), but hopefully talking about it here in a more casual format which doesn’t have to appease any reviewers can make it more digestible than the fairly opaque (and error ridden) notes.
Also, as an aside, I highly doubt this will be practically useful for anything directly :), but it was fun to think about.
Dirichlet Processes:
Dirichlet Processes (DPs) are stochastic processes which for which realizations from a DP are almost-surely discrete distributions over some measurable space. That is, assuming 

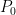




The primary defining characteristic of a DP is that the distribution of the amount of mass assigned to each element of a mutually exclusive and exhaustive partition 

However, there is a constructive definition of a measure defined using a DP called the Sutheraman representation [1] for which the proof of the Sethuraman representation (which is omitted in this post) shows that realizations of the DP are almost surely discrete.

With 




So we can see that each realization from a DP is a almost-surely discrete probability distribution.
Spatial Dirichlet Process:
Recall that we said that the DP requires a measure and a concentration parameter 


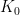


This allows us to metricize the space and induce a topology which can then be extended to a measurable space with the Borel sets defined on the topology.
The spatial DP is a DP with a spatial process as the base measure, and for the sake of this post we’ll be considering GPs as the base measure. This is expressed as follows, restricting ourselves to mean zero GPs for the sake of exposition:

Then the Sethuraman representation of this would be:

Where 

This allows us to introduce the following theorem:
Theorem 1:
Suppose we have a spatial DP with base measure 


![\mathbb{E}_{g |\{\pi_j\}_{j=1}^\infty}[g | \{\pi_j\}_{j=1}^\infty] \overset{P| \{\pi_j\}_{j=1}^\infty}{\sim} GP(0, (\sum_{j=1}^\infty \pi_j^2)K)](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D_%7Bg+%7C%5C%7B%5Cpi_j%5C%7D_%7Bj%3D1%7D%5E%5Cinfty%7D%5Bg+%7C+%5C%7B%5Cpi_j%5C%7D_%7Bj%3D1%7D%5E%5Cinfty%5D+%5Coverset%7BP%7C+%5C%7B%5Cpi_j%5C%7D_%7Bj%3D1%7D%5E%5Cinfty%7D%7B%5Csim%7D+GP%280%2C+%28%5Csum_%7Bj%3D1%7D%5E%5Cinfty+%5Cpi_j%5E2%29K%29&bg=ffffff&fg=000&s=0&c=20201002)
Where 

What this is saying is that if we take the expectation of the random measures conditioned on both the measure itself (which is drawn from a spatial DP), and the weights, then we get a gaussian process. I think this is fairly intuitive but proving it requires some hoops to jump through.
Proof:
The proof relies on Theorem 1.1 here [3], the moment result introduced here [4], the Borell Cantelli lemma, and the Kolmogorov Extension Theorem.
We have that 



Let 


Note that ![\mathbb{E}_{\{\theta_j\}_{j=1}^n}[P_n(B)] =\mathbb{E}_{\{\theta_j\}_{j=1}^n}[\sum_{j=1}^n \pi_j \delta_{\theta_j}(B)]](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D_%7B%5C%7B%5Ctheta_j%5C%7D_%7Bj%3D1%7D%5En%7D%5BP_n%28B%29%5D+%3D%5Cmathbb%7BE%7D_%7B%5C%7B%5Ctheta_j%5C%7D_%7Bj%3D1%7D%5En%7D%5B%5Csum_%7Bj%3D1%7D%5En+%5Cpi_j+%5Cdelta_%7B%5Ctheta_j%7D%28B%29%5D+&bg=ffffff&fg=000&s=0&c=20201002)
![\mathbb{E}_{\{\theta_j\}_{j=1}^n}[\sum_{j=1}^n \pi_j \delta_{\theta_j}(B)] = \mathbb{E}_{\{\theta_j\}_{j=1}^n}[\sum_{j=1}^n \pi_j I_{(\theta_j \in B)}]](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D_%7B%5C%7B%5Ctheta_j%5C%7D_%7Bj%3D1%7D%5En%7D%5B%5Csum_%7Bj%3D1%7D%5En+%5Cpi_j+%5Cdelta_%7B%5Ctheta_j%7D%28B%29%5D+%3D++%5Cmathbb%7BE%7D_%7B%5C%7B%5Ctheta_j%5C%7D_%7Bj%3D1%7D%5En%7D%5B%5Csum_%7Bj%3D1%7D%5En+%5Cpi_j+I_%7B%28%5Ctheta_j+%5Cin+B%29%7D%5D&bg=ffffff&fg=000&s=0&c=20201002)

But we have that

Note that this sum is less than or equal to 

We proceed to use Borell cantelli to show almost sure convergence in the limit
Note that 



Specifically, using the principle result introduced in the introduction in [4] we have that, for independent random variables 


![\mathbb{E}[\pi_j'\prod_{k=1}^{j-1}(1-\pi_k')] = \mathbb{E}_{\pi_j'}[\pi_j']\prod_{k=1}^{j-1}\mathbb{E}_{\pi_k'}[(1-\pi_k')]](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5B%5Cpi_j%27%5Cprod_%7Bk%3D1%7D%5E%7Bj-1%7D%281-%5Cpi_k%27%29%5D+%3D+%5Cmathbb%7BE%7D_%7B%5Cpi_j%27%7D%5B%5Cpi_j%27%5D%5Cprod_%7Bk%3D1%7D%5E%7Bj-1%7D%5Cmathbb%7BE%7D_%7B%5Cpi_k%27%7D%5B%281-%5Cpi_k%27%29%5D&bg=ffffff&fg=000&s=0&c=20201002)
This gives us that the expectation of 
The Borel Canteli is satisfied if 

The limit is 0 which gives us that in the limit 
We showed this is true for all Borel sets, and this includes closed sets, so select arbitrary individual singleton sets of
Pick a set of individual elements in 


Noting that the selection of the marginals was arbitrary, the limit exists and is a Gaussian process for all marginals, the Kolmogorov extension theorem shows that the limit process exists and is a Gaussian process.

This theorem also introduces some interesting intuition about “what a spatial DP is”. Note that if we mix on 






Wasserstein Metric:
Examine the metric space 


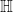


![W_p(\mathbb{G},\mathbb{H}) = \inf_{\gamma \in \Gamma(\mathbb{G},\mathbb{H})}\mathbb{E}_{g,h \sim \gamma}[d(g,h)^p]^{\frac{1}{p}}](https://s0.wp.com/latex.php?latex=W_p%28%5Cmathbb%7BG%7D%2C%5Cmathbb%7BH%7D%29+%3D+%5Cinf_%7B%5Cgamma+%5Cin+%5CGamma%28%5Cmathbb%7BG%7D%2C%5Cmathbb%7BH%7D%29%7D%5Cmathbb%7BE%7D_%7Bg%2Ch+%5Csim+%5Cgamma%7D%5Bd%28g%2Ch%29%5Ep%5D%5E%7B%5Cfrac%7B1%7D%7Bp%7D%7D&bg=ffffff&fg=000&s=0&c=20201002)
Where 

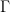
Suppose 


Where the distance metric on the metric space on which 





Theorem 2 (REVISIT, NEEDS SOME WORK):
Suppose 
![c(\eta) = \mathbf{E}_{g \sim \eta}[\mathbb{E}_{h\sim g}[||h||_{L_1}]]\geq 0](https://s0.wp.com/latex.php?latex=c%28%5Ceta%29+%3D+%5Cmathbf%7BE%7D_%7Bg+%5Csim+%5Ceta%7D%5B%5Cmathbb%7BE%7D_%7Bh%5Csim+g%7D%5B%7C%7Ch%7C%7C_%7BL_1%7D%5D%5D%5Cgeq+0&bg=ffffff&fg=000&s=0&c=20201002)
![a(\alpha) = \mathbb{E}_{h\sim P}[\mathbb{E}_{h}[||h||_{L_1}]] >0](https://s0.wp.com/latex.php?latex=a%28%5Calpha%29+%3D+%5Cmathbb%7BE%7D_%7Bh%5Csim+P%7D%5B%5Cmathbb%7BE%7D_%7Bh%7D%5B%7C%7Ch%7C%7C_%7BL_1%7D%5D%5D+%3E0+&bg=ffffff&fg=000&s=0&c=20201002)

![W_{p,W_{r, ||\circ||_{L_1}}}(\eta, P) \geq \min\{|c(\eta) -\mathbb{E}_{\{\pi_j\}_{j=1}^\infty}[\exp[\frac{-\mathbb{E}_{g|\{\pi_j\}_{j=1}^\infty}[||g||_{L_1}]^2}{\sigma^2_T}]] -a(\alpha)|,|c(\eta) - a(\alpha)| \}](https://s0.wp.com/latex.php?latex=W_%7Bp%2CW_%7Br%2C+%7C%7C%5Ccirc%7C%7C_%7BL_1%7D%7D%7D%28%5Ceta%2C+P%29+%5Cgeq+%5Cmin%5C%7B%7Cc%28%5Ceta%29+-%5Cmathbb%7BE%7D_%7B%5C%7B%5Cpi_j%5C%7D_%7Bj%3D1%7D%5E%5Cinfty%7D%5B%5Cexp%5B%5Cfrac%7B-%5Cmathbb%7BE%7D_%7Bg%7C%5C%7B%5Cpi_j%5C%7D_%7Bj%3D1%7D%5E%5Cinfty%7D%5B%7C%7Cg%7C%7C_%7BL_1%7D%5D%5E2%7D%7B%5Csigma%5E2_T%7D%5D%5D+-a%28%5Calpha%29%7C%2C%7Cc%28%5Ceta%29+-+a%28%5Calpha%29%7C+%5C%7D&bg=ffffff&fg=000&s=0&c=20201002)
Proof:
What we’re interested in examining is:
![W_{p,W_{r, ||\circ||_{L_1}}}(\eta, P) = \inf_{\gamma \in \Gamma(\eta,P)}\mathbb{E}_{g,h \sim \gamma}[W_{r,||\circ||_{L_1}}(g,h)^p]^{\frac{1}{p}}](https://s0.wp.com/latex.php?latex=W_%7Bp%2CW_%7Br%2C+%7C%7C%5Ccirc%7C%7C_%7BL_1%7D%7D%7D%28%5Ceta%2C+P%29+%3D+%5Cinf_%7B%5Cgamma+%5Cin+%5CGamma%28%5Ceta%2CP%29%7D%5Cmathbb%7BE%7D_%7Bg%2Ch+%5Csim+%5Cgamma%7D%5BW_%7Br%2C%7C%7C%5Ccirc%7C%7C_%7BL_1%7D%7D%28g%2Ch%29%5Ep%5D%5E%7B%5Cfrac%7B1%7D%7Bp%7D%7D&bg=ffffff&fg=000&s=0&c=20201002)
Jensen’s inequality allows us to remove the exponential and it cancels with the root.
![\Rightarrow \inf_{\gamma \in \Gamma(\eta,P)}\mathbb{E}_{g,h \sim \gamma}[W_{r,||\circ||_{L_1}}(g,h)] = \inf_{\gamma \in \Gamma(\eta,P)}\mathbb{E}_{g,h \sim \gamma}[\inf_{\psi \in \Psi(g,h)}\mathbb{E}_{q,u\sim \psi}[ ||q-u||_{L_1}^r]^{\frac{1}{r}}]](https://s0.wp.com/latex.php?latex=%5CRightarrow+%5Cinf_%7B%5Cgamma+%5Cin+%5CGamma%28%5Ceta%2CP%29%7D%5Cmathbb%7BE%7D_%7Bg%2Ch+%5Csim+%5Cgamma%7D%5BW_%7Br%2C%7C%7C%5Ccirc%7C%7C_%7BL_1%7D%7D%28g%2Ch%29%5D+%3D+%5Cinf_%7B%5Cgamma+%5Cin+%5CGamma%28%5Ceta%2CP%29%7D%5Cmathbb%7BE%7D_%7Bg%2Ch+%5Csim+%5Cgamma%7D%5B%5Cinf_%7B%5Cpsi+%5Cin+%5CPsi%28g%2Ch%29%7D%5Cmathbb%7BE%7D_%7Bq%2Cu%5Csim+%5Cpsi%7D%5B++++++%7C%7Cq-u%7C%7C_%7BL_1%7D%5Er%5D%5E%7B%5Cfrac%7B1%7D%7Br%7D%7D%5D&bg=ffffff&fg=000&s=0&c=20201002)
Once again Jensen’s inequality allows us to get rid of the exponential and root in 
![W_{p,W_{r, ||\circ||_{L_1}}}(\eta, P) \geq \inf_{\gamma \in \Gamma(\eta,P)}\mathbb{E}_{g,h \sim \gamma}[\inf_{\psi \in \Psi(g,h)}\mathbb{E}_{q,u\sim \psi}[|||q||_{L_1}-||u||_{L_1}|]]](https://s0.wp.com/latex.php?latex=W_%7Bp%2CW_%7Br%2C+%7C%7C%5Ccirc%7C%7C_%7BL_1%7D%7D%7D%28%5Ceta%2C+P%29+%5Cgeq+%5Cinf_%7B%5Cgamma+%5Cin+%5CGamma%28%5Ceta%2CP%29%7D%5Cmathbb%7BE%7D_%7Bg%2Ch+%5Csim+%5Cgamma%7D%5B%5Cinf_%7B%5Cpsi+%5Cin+%5CPsi%28g%2Ch%29%7D%5Cmathbb%7BE%7D_%7Bq%2Cu%5Csim+%5Cpsi%7D%5B%7C%7C%7Cq%7C%7C_%7BL_1%7D-%7C%7Cu%7C%7C_%7BL_1%7D%7C%5D%5D&bg=ffffff&fg=000&s=0&c=20201002)
Applying Jensen’s inequality we get:
![W_{p,W_{r, ||\circ||_{L_1}}}(\eta, P) \geq \inf_{\gamma \in \Gamma(\eta,P)}\mathbb{E}_{g,h \sim \gamma}[\inf_{\psi \in \Psi(g,h)}|\mathbb{E}_{q,u\sim \psi}[||q||_{L_1}-||u||_{L_1}]|]](https://s0.wp.com/latex.php?latex=W_%7Bp%2CW_%7Br%2C+%7C%7C%5Ccirc%7C%7C_%7BL_1%7D%7D%7D%28%5Ceta%2C+P%29+%5Cgeq+%5Cinf_%7B%5Cgamma+%5Cin+%5CGamma%28%5Ceta%2CP%29%7D%5Cmathbb%7BE%7D_%7Bg%2Ch+%5Csim+%5Cgamma%7D%5B%5Cinf_%7B%5Cpsi+%5Cin+%5CPsi%28g%2Ch%29%7D%7C%5Cmathbb%7BE%7D_%7Bq%2Cu%5Csim+%5Cpsi%7D%5B%7C%7Cq%7C%7C_%7BL_1%7D-%7C%7Cu%7C%7C_%7BL_1%7D%5D%7C%5D&bg=ffffff&fg=000&s=0&c=20201002)
The expectation factors and we get:
![W_{p,W_{r, ||\circ||_{L_1}}}(\eta, P) \geq \inf_{\gamma \in \Gamma(\eta,P)}\mathbb{E}_{g,h \sim \gamma}[\inf_{\psi \in \Psi(g,h)}|\mathbb{E}_{q\sim \psi_1}[||q||_{L_1}]-\mathbb{E}_{u\sim \psi_2}[||u||_{L_1}]|]](https://s0.wp.com/latex.php?latex=W_%7Bp%2CW_%7Br%2C+%7C%7C%5Ccirc%7C%7C_%7BL_1%7D%7D%7D%28%5Ceta%2C+P%29+%5Cgeq+%5Cinf_%7B%5Cgamma+%5Cin+%5CGamma%28%5Ceta%2CP%29%7D%5Cmathbb%7BE%7D_%7Bg%2Ch+%5Csim+%5Cgamma%7D%5B%5Cinf_%7B%5Cpsi+%5Cin+%5CPsi%28g%2Ch%29%7D%7C%5Cmathbb%7BE%7D_%7Bq%5Csim+%5Cpsi_1%7D%5B%7C%7Cq%7C%7C_%7BL_1%7D%5D-%5Cmathbb%7BE%7D_%7Bu%5Csim+%5Cpsi_2%7D%5B%7C%7Cu%7C%7C_%7BL_1%7D%5D%7C%5D&bg=ffffff&fg=000&s=0&c=20201002)
Noting that the marginals of 


![W_{p,W_{r, ||\circ||_{L_1}}}(\eta, P) \geq \inf_{\gamma \in \Gamma(\eta,P)}\mathbb{E}_{g,h \sim \gamma}[|\mathbb{E}_{g}[||g||_{L_1}]-\mathbb{E}_h[||h||_{L_1}]|]](https://s0.wp.com/latex.php?latex=W_%7Bp%2CW_%7Br%2C+%7C%7C%5Ccirc%7C%7C_%7BL_1%7D%7D%7D%28%5Ceta%2C+P%29+%5Cgeq+%5Cinf_%7B%5Cgamma+%5Cin+%5CGamma%28%5Ceta%2CP%29%7D%5Cmathbb%7BE%7D_%7Bg%2Ch+%5Csim+%5Cgamma%7D%5B%7C%5Cmathbb%7BE%7D_%7Bg%7D%5B%7C%7Cg%7C%7C_%7BL_1%7D%5D-%5Cmathbb%7BE%7D_h%5B%7C%7Ch%7C%7C_%7BL_1%7D%5D%7C%5D&bg=ffffff&fg=000&s=0&c=20201002)
Applying Jensen’s inequality again, we get:
![W_{p,W_{r, ||\circ||_{L_1}}}(\eta, P) \geq \inf_{\gamma \in \Gamma(\eta,P)}|\mathbb{E}_{g,h \sim \gamma}[\mathbb{E}_{g}[||g||_{L_1}]-\mathbb{E}_h[||h||_{L_1}]]|](https://s0.wp.com/latex.php?latex=W_%7Bp%2CW_%7Br%2C+%7C%7C%5Ccirc%7C%7C_%7BL_1%7D%7D%7D%28%5Ceta%2C+P%29+%5Cgeq+%5Cinf_%7B%5Cgamma+%5Cin+%5CGamma%28%5Ceta%2CP%29%7D%7C%5Cmathbb%7BE%7D_%7Bg%2Ch+%5Csim+%5Cgamma%7D%5B%5Cmathbb%7BE%7D_%7Bg%7D%5B%7C%7Cg%7C%7C_%7BL_1%7D%5D-%5Cmathbb%7BE%7D_h%5B%7C%7Ch%7C%7C_%7BL_1%7D%5D%5D%7C&bg=ffffff&fg=000&s=0&c=20201002)
The left side double expectation is some positive constant 
![W_{p,W_{r, ||\circ||_{L_1}}}(\eta, P) \geq \inf_{\gamma \in \Gamma(\eta,P)}|c -\mathbb{E}_{\{\pi_j\}_{j=1^\infty}}[\mathbb{E}_{h | \{\pi_j\}_{j=1}^\infty}[||h||_{L_1}]]|](https://s0.wp.com/latex.php?latex=W_%7Bp%2CW_%7Br%2C+%7C%7C%5Ccirc%7C%7C_%7BL_1%7D%7D%7D%28%5Ceta%2C+P%29+%5Cgeq+%5Cinf_%7B%5Cgamma+%5Cin+%5CGamma%28%5Ceta%2CP%29%7D%7Cc+-%5Cmathbb%7BE%7D_%7B%5C%7B%5Cpi_j%5C%7D_%7Bj%3D1%5E%5Cinfty%7D%7D%5B%5Cmathbb%7BE%7D_%7Bh+%7C+%5C%7B%5Cpi_j%5C%7D_%7Bj%3D1%7D%5E%5Cinfty%7D%5B%7C%7Ch%7C%7C_%7BL_1%7D%5D%5D%7C&bg=ffffff&fg=000&s=0&c=20201002)
Note here that we used the conditional expectation as in Theorem 1, conditioning first on
Note that for an expectation ![\mathbb{E}_X[x]](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D_X%5Bx%5D&bg=ffffff&fg=000&s=0&c=20201002)
![\mathbb{E}_X[x] = \int_{-\infty}^\infty (1-F_X(x))dx](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D_X%5Bx%5D+%3D+%5Cint_%7B-%5Cinfty%7D%5E%5Cinfty+%281-F_X%28x%29%29dx&bg=ffffff&fg=000&s=0&c=20201002)
We also have the Borell-TIS inequality for Gaussian processes:
Proposition 1, Borel-TIS Inequality:
Let 

![\sigma^2_{\mathbf{T}} = \sup_{t\in\mathbf{T}}\mathbb{E}[|f_t|^2]](https://s0.wp.com/latex.php?latex=%5Csigma%5E2_%7B%5Cmathbf%7BT%7D%7D+%3D+%5Csup_%7Bt%5Cin%5Cmathbf%7BT%7D%7D%5Cmathbb%7BE%7D%5B%7Cf_t%7C%5E2%5D&bg=ffffff&fg=000&s=0&c=20201002)
![P(||f||_T > \mathbb{E}[||f||_T] + u) \leq \exp[\frac{-u^2}{\sigma^2_T}]](https://s0.wp.com/latex.php?latex=P%28%7C%7Cf%7C%7C_T+%3E+%5Cmathbb%7BE%7D%5B%7C%7Cf%7C%7C_T%5D+%2B+u%29+%5Cleq+%5Cexp%5B%5Cfrac%7B-u%5E2%7D%7B%5Csigma%5E2_T%7D%5D&bg=ffffff&fg=000&s=0&c=20201002)
for 
Suppose for purpose of examination that 
![W_{p,W_{r, ||\circ||_{L_1}}}(\eta, P) \geq \inf_{\gamma \in \Gamma(\eta,P)}|c -\mathbb{E}_{\{\pi_j\}_{j=1}^\infty}[\int_{\mathbb{E}_{g|\{\pi_j\}_{j=1}^\infty}[||g||_{L_1}]}^\infty P(||g||_{L_1} > u)du - \int_{0}^{\mathbb{E}_{g|\{\pi_j\}_{j=1}^\infty}[||g||_{L_1}]} P_{g | \{\pi_j\}_{j=1}^\infty}(||g||_{L_1} > u)du]|](https://s0.wp.com/latex.php?latex=W_%7Bp%2CW_%7Br%2C+%7C%7C%5Ccirc%7C%7C_%7BL_1%7D%7D%7D%28%5Ceta%2C+P%29+%5Cgeq+%5Cinf_%7B%5Cgamma+%5Cin+%5CGamma%28%5Ceta%2CP%29%7D%7Cc+-%5Cmathbb%7BE%7D_%7B%5C%7B%5Cpi_j%5C%7D_%7Bj%3D1%7D%5E%5Cinfty%7D%5B%5Cint_%7B%5Cmathbb%7BE%7D_%7Bg%7C%5C%7B%5Cpi_j%5C%7D_%7Bj%3D1%7D%5E%5Cinfty%7D%5B%7C%7Cg%7C%7C_%7BL_1%7D%5D%7D%5E%5Cinfty+P%28%7C%7Cg%7C%7C_%7BL_1%7D+%3E+u%29du+-+%5Cint_%7B0%7D%5E%7B%5Cmathbb%7BE%7D_%7Bg%7C%5C%7B%5Cpi_j%5C%7D_%7Bj%3D1%7D%5E%5Cinfty%7D%5B%7C%7Cg%7C%7C_%7BL_1%7D%5D%7D+P_%7Bg+%7C+%5C%7B%5Cpi_j%5C%7D_%7Bj%3D1%7D%5E%5Cinfty%7D%28%7C%7Cg%7C%7C_%7BL_1%7D+%3E+u%29du%5D%7C&bg=ffffff&fg=000&s=0&c=20201002)
Do a change of variables on the first integral to get:
![W_{p,W_{r, ||\circ||_{L_1}}}(\eta, P) \geq \inf_{\gamma \in \Gamma(\eta,P)}|c -\mathbb{E}_{\{\pi_j\}_{j=1}^\infty}[\int_0^\infty P(||g||_{L_1} > \mathbb{E}_{g|\{\pi_j\}_{j=1}^\infty}[||g||_{L_1}] + u)du - \int_{0}^{\mathbb{E}_{g|\{\pi_j\}_{j=1}^\infty}[||g||_{L_1}]} P_{g | \{\pi_j\}_{j=1}^\infty}(||g||_{L_1} > u)du]|](https://s0.wp.com/latex.php?latex=W_%7Bp%2CW_%7Br%2C+%7C%7C%5Ccirc%7C%7C_%7BL_1%7D%7D%7D%28%5Ceta%2C+P%29+%5Cgeq+%5Cinf_%7B%5Cgamma+%5Cin+%5CGamma%28%5Ceta%2CP%29%7D%7Cc+-%5Cmathbb%7BE%7D_%7B%5C%7B%5Cpi_j%5C%7D_%7Bj%3D1%7D%5E%5Cinfty%7D%5B%5Cint_0%5E%5Cinfty+P%28%7C%7Cg%7C%7C_%7BL_1%7D+%3E+%5Cmathbb%7BE%7D_%7Bg%7C%5C%7B%5Cpi_j%5C%7D_%7Bj%3D1%7D%5E%5Cinfty%7D%5B%7C%7Cg%7C%7C_%7BL_1%7D%5D+%2B+u%29du+-+%5Cint_%7B0%7D%5E%7B%5Cmathbb%7BE%7D_%7Bg%7C%5C%7B%5Cpi_j%5C%7D_%7Bj%3D1%7D%5E%5Cinfty%7D%5B%7C%7Cg%7C%7C_%7BL_1%7D%5D%7D+P_%7Bg+%7C+%5C%7B%5Cpi_j%5C%7D_%7Bj%3D1%7D%5E%5Cinfty%7D%28%7C%7Cg%7C%7C_%7BL_1%7D+%3E+u%29du%5D%7C&bg=ffffff&fg=000&s=0&c=20201002)
Use the Borel-TIS inequality on the integrand of the first integral to obtain:
![W_{p,W_{r, ||\circ||_{L_1}}}(\eta, P) \geq \inf_{\gamma \in \Gamma(\eta,P)}|c -\mathbb{E}_{\{\pi_j\}_{j=1}^\infty}[\int_0^\infty \exp[\frac{-u}{\sigma^2_T}]du - \int_{0}^{\mathbb{E}_{g|\{\pi_j\}_{j=1}^\infty}[||g||_{L_1}]} P_{g | \{\pi_j\}_{j=1}^\infty}(||g||_{L_1} > u)du]|](https://s0.wp.com/latex.php?latex=W_%7Bp%2CW_%7Br%2C+%7C%7C%5Ccirc%7C%7C_%7BL_1%7D%7D%7D%28%5Ceta%2C+P%29+%5Cgeq+%5Cinf_%7B%5Cgamma+%5Cin+%5CGamma%28%5Ceta%2CP%29%7D%7Cc+-%5Cmathbb%7BE%7D_%7B%5C%7B%5Cpi_j%5C%7D_%7Bj%3D1%7D%5E%5Cinfty%7D%5B%5Cint_0%5E%5Cinfty+%5Cexp%5B%5Cfrac%7B-u%7D%7B%5Csigma%5E2_T%7D%5Ddu+-+%5Cint_%7B0%7D%5E%7B%5Cmathbb%7BE%7D_%7Bg%7C%5C%7B%5Cpi_j%5C%7D_%7Bj%3D1%7D%5E%5Cinfty%7D%5B%7C%7Cg%7C%7C_%7BL_1%7D%5D%7D+P_%7Bg+%7C+%5C%7B%5Cpi_j%5C%7D_%7Bj%3D1%7D%5E%5Cinfty%7D%28%7C%7Cg%7C%7C_%7BL_1%7D+%3E+u%29du%5D%7C&bg=ffffff&fg=000&s=0&c=20201002)
Integrating the exponential we get:
![W_{p,W_{r, ||\circ||_{L_1}}}(\eta, P) \geq \inf_{\gamma \in \Gamma(\eta,P)}|c +\mathbb{E}_{\{\pi_j\}_{j=1}^\infty}[\sigma^2_T \exp[\frac{-u}{\sigma^2_T}]|_{0}^\infty - \int_{0}^{\mathbb{E}_{g|\{\pi_j\}_{j=1}^\infty}[||g||_{L_1}]} P_{g | \{\pi_j\}_{j=1}^\infty}(||g||_{L_1} > u)du]|](https://s0.wp.com/latex.php?latex=W_%7Bp%2CW_%7Br%2C+%7C%7C%5Ccirc%7C%7C_%7BL_1%7D%7D%7D%28%5Ceta%2C+P%29+%5Cgeq+%5Cinf_%7B%5Cgamma+%5Cin+%5CGamma%28%5Ceta%2CP%29%7D%7Cc+%2B%5Cmathbb%7BE%7D_%7B%5C%7B%5Cpi_j%5C%7D_%7Bj%3D1%7D%5E%5Cinfty%7D%5B%5Csigma%5E2_T+%5Cexp%5B%5Cfrac%7B-u%7D%7B%5Csigma%5E2_T%7D%5D%7C_%7B0%7D%5E%5Cinfty+-+%5Cint_%7B0%7D%5E%7B%5Cmathbb%7BE%7D_%7Bg%7C%5C%7B%5Cpi_j%5C%7D_%7Bj%3D1%7D%5E%5Cinfty%7D%5B%7C%7Cg%7C%7C_%7BL_1%7D%5D%7D+P_%7Bg+%7C+%5C%7B%5Cpi_j%5C%7D_%7Bj%3D1%7D%5E%5Cinfty%7D%28%7C%7Cg%7C%7C_%7BL_1%7D+%3E+u%29du%5D%7C&bg=ffffff&fg=000&s=0&c=20201002)
![W_{p,W_{r, ||\circ||_{L_1}}}(\eta, P) \geq \inf_{\gamma \in \Gamma(\eta,P)}|c -\mathbb{E}_{\{\pi_j\}_{j=1}^\infty}[\sigma^2_T] - \mathbb{E}_{\{\pi_j\}_{j=1}^\infty}[\int_{0}^{\mathbb{E}_{g|\{\pi_j\}_{j=1}^\infty}[||g||_{L_1}]} P_{g | \{\pi_j\}_{j=1}^\infty}(||g||_{L_1} > u)du]|](https://s0.wp.com/latex.php?latex=W_%7Bp%2CW_%7Br%2C+%7C%7C%5Ccirc%7C%7C_%7BL_1%7D%7D%7D%28%5Ceta%2C+P%29+%5Cgeq+%5Cinf_%7B%5Cgamma+%5Cin+%5CGamma%28%5Ceta%2CP%29%7D%7Cc+-%5Cmathbb%7BE%7D_%7B%5C%7B%5Cpi_j%5C%7D_%7Bj%3D1%7D%5E%5Cinfty%7D%5B%5Csigma%5E2_T%5D+-+%5Cmathbb%7BE%7D_%7B%5C%7B%5Cpi_j%5C%7D_%7Bj%3D1%7D%5E%5Cinfty%7D%5B%5Cint_%7B0%7D%5E%7B%5Cmathbb%7BE%7D_%7Bg%7C%5C%7B%5Cpi_j%5C%7D_%7Bj%3D1%7D%5E%5Cinfty%7D%5B%7C%7Cg%7C%7C_%7BL_1%7D%5D%7D+P_%7Bg+%7C+%5C%7B%5Cpi_j%5C%7D_%7Bj%3D1%7D%5E%5Cinfty%7D%28%7C%7Cg%7C%7C_%7BL_1%7D+%3E+u%29du%5D%7C&bg=ffffff&fg=000&s=0&c=20201002)
Multiplying the inside of the absolute value by 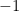
![W_{p,W_{r, ||\circ||_{L_1}}}(\eta, P) \geq \inf_{\gamma \in \Gamma(\eta,P)}|c -\mathbb{E}_{\{\pi_j\}_{j=1}^\infty}[\sigma^2_T]|](https://s0.wp.com/latex.php?latex=W_%7Bp%2CW_%7Br%2C+%7C%7C%5Ccirc%7C%7C_%7BL_1%7D%7D%7D%28%5Ceta%2C+P%29+%5Cgeq+%5Cinf_%7B%5Cgamma+%5Cin+%5CGamma%28%5Ceta%2CP%29%7D%7Cc+-%5Cmathbb%7BE%7D_%7B%5C%7B%5Cpi_j%5C%7D_%7Bj%3D1%7D%5E%5Cinfty%7D%5B%5Csigma%5E2_T%5D%7C&bg=ffffff&fg=000&s=0&c=20201002)
Which is constant with respect to the infimum so this gives us:
![W_{p,W_{r, ||\circ||_{L_1}}}(\eta, P) \geq |c -\mathbb{E}_{\{\pi_j\}_{j=1}^\infty}[\sigma^2_T]|](https://s0.wp.com/latex.php?latex=W_%7Bp%2CW_%7Br%2C+%7C%7C%5Ccirc%7C%7C_%7BL_1%7D%7D%7D%28%5Ceta%2C+P%29+%5Cgeq+%7Cc+-%5Cmathbb%7BE%7D_%7B%5C%7B%5Cpi_j%5C%7D_%7Bj%3D1%7D%5E%5Cinfty%7D%5B%5Csigma%5E2_T%5D%7C&bg=ffffff&fg=000&s=0&c=20201002)
Taking the 

![W_{p,W_{r, ||\circ||_{L_1}}}(\eta, P) \geq |c -\mathbb{E}_{\{\pi_j\}_{j=1}^\infty}[(\sum_{j=1}^\infty \pi_j^2)\mathbb{E}_{g | \{\pi_j\}_{j=1}^\infty}[\sup_{t \in \mathbf{T}}|g(t)|^2]]|](https://s0.wp.com/latex.php?latex=W_%7Bp%2CW_%7Br%2C+%7C%7C%5Ccirc%7C%7C_%7BL_1%7D%7D%7D%28%5Ceta%2C+P%29+%5Cgeq+%7Cc+-%5Cmathbb%7BE%7D_%7B%5C%7B%5Cpi_j%5C%7D_%7Bj%3D1%7D%5E%5Cinfty%7D%5B%28%5Csum_%7Bj%3D1%7D%5E%5Cinfty+%5Cpi_j%5E2%29%5Cmathbb%7BE%7D_%7Bg+%7C+%5C%7B%5Cpi_j%5C%7D_%7Bj%3D1%7D%5E%5Cinfty%7D%5B%5Csup_%7Bt+%5Cin+%5Cmathbf%7BT%7D%7D%7Cg%28t%29%7C%5E2%5D%5D%7C&bg=ffffff&fg=000&s=0&c=20201002)
Examining the theorem, note that we can reproduce everything we did for the spatial DP for another spatial DP as 

![W_{p,W_{r, ||\circ||_{L_1}}}(\eta, P) \geq |\mathbb{E}_{\{\pi^{(1)}_j\}_{j=1}^\infty}[(\sum_{j=1}^\infty \pi_j^{(1)^2})\mathbb{E}_{g^{(1)} | K_0^{(1)}}[\sup_{t \in \mathbf{T}}|g^{(1)}(t)|^2]] -\mathbb{E}_{\{\pi^{(2)}_j\}_{j=1}^\infty}[(\sum_{j=1}^\infty \pi_j^{(2)^2})\mathbb{E}_{g^{(2)} |K_0^{(2)}}[\sup_{t \in \mathbf{T}}|g^{(2)}(t)|^2]]|](https://s0.wp.com/latex.php?latex=W_%7Bp%2CW_%7Br%2C+%7C%7C%5Ccirc%7C%7C_%7BL_1%7D%7D%7D%28%5Ceta%2C+P%29+%5Cgeq+%7C%5Cmathbb%7BE%7D_%7B%5C%7B%5Cpi%5E%7B%281%29%7D_j%5C%7D_%7Bj%3D1%7D%5E%5Cinfty%7D%5B%28%5Csum_%7Bj%3D1%7D%5E%5Cinfty+%5Cpi_j%5E%7B%281%29%5E2%7D%29%5Cmathbb%7BE%7D_%7Bg%5E%7B%281%29%7D+%7C+K_0%5E%7B%281%29%7D%7D%5B%5Csup_%7Bt+%5Cin+%5Cmathbf%7BT%7D%7D%7Cg%5E%7B%281%29%7D%28t%29%7C%5E2%5D%5D+-%5Cmathbb%7BE%7D_%7B%5C%7B%5Cpi%5E%7B%282%29%7D_j%5C%7D_%7Bj%3D1%7D%5E%5Cinfty%7D%5B%28%5Csum_%7Bj%3D1%7D%5E%5Cinfty+%5Cpi_j%5E%7B%282%29%5E2%7D%29%5Cmathbb%7BE%7D_%7Bg%5E%7B%282%29%7D+%7CK_0%5E%7B%282%29%7D%7D%5B%5Csup_%7Bt+%5Cin+%5Cmathbf%7BT%7D%7D%7Cg%5E%7B%282%29%7D%28t%29%7C%5E2%5D%5D%7C&bg=ffffff&fg=000&s=0&c=20201002)
Wasserstein Distance as Linear Program Between Two Spatial DPs:
We exploit the linear programming representation of optimal transport but extend it to infinite dimensional matrices (an operator on a countably infinite set). You can read more about optimal transport between finite discrete distributions in that previously linked blog post, but the general idea we’re going to do is note that for discrete distributions 


where 



Where 
Then the Wasserstein distance between these two discrete distributions is:

Extending this to countably infinite discrete distributions we get:

subject to:



Proof:
Note for myself to finish this. The minimizer of the expectation over all joint distributions on the atoms and weights of this expression is the Wasserstein distance between two spatial dirichlet processes. Use self similarity of the DP to do an iterative conditional expectation to reduce down the inside term. With the conditional expectation iterating we get an iterative linear program for increasing dimension of 


Truncation Bounds:
The final and last theorem is related to the error of the truncation. This is going to heavily rely on Proposition 1.
Truncation means that supposing that we sample 

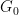




By the Borel-TIS inequality we have: ![P_{P | \{\pi_j\}_{j=1}^\infty}(|| \mathbb{E}_{g | \{\pi_j\}_{j=1}^\infty}[g-g_n]||_{L_1}] > \mathbb{E}_{P | \{\pi_j\}_{j=1}^\infty}[||\mathbb{E}_{g | \{\pi_j\}_{j=1}^\infty}[g - g_n]||_{L_1}]] + t)\leq \exp[\frac{-t^2}{(\sum_{j=n+1}^\infty \pi_j^2) \sigma^2_\mathbf{T}}]](https://s0.wp.com/latex.php?latex=P_%7BP+%7C+%5C%7B%5Cpi_j%5C%7D_%7Bj%3D1%7D%5E%5Cinfty%7D%28%7C%7C+%5Cmathbb%7BE%7D_%7Bg+%7C+%5C%7B%5Cpi_j%5C%7D_%7Bj%3D1%7D%5E%5Cinfty%7D%5Bg-g_n%5D%7C%7C_%7BL_1%7D%5D+%3E+%5Cmathbb%7BE%7D_%7BP+%7C+%5C%7B%5Cpi_j%5C%7D_%7Bj%3D1%7D%5E%5Cinfty%7D%5B%7C%7C%5Cmathbb%7BE%7D_%7Bg+%7C+%5C%7B%5Cpi_j%5C%7D_%7Bj%3D1%7D%5E%5Cinfty%7D%5Bg+-+g_n%5D%7C%7C_%7BL_1%7D%5D%5D+%2B+t%29%5Cleq+%5Cexp%5B%5Cfrac%7B-t%5E2%7D%7B%28%5Csum_%7Bj%3Dn%2B1%7D%5E%5Cinfty+%5Cpi_j%5E2%29+%5Csigma%5E2_%5Cmathbf%7BT%7D%7D%5D&bg=ffffff&fg=000&s=0&c=20201002)
![\mathbb{E}_{g | \{\pi_j\}_{j=1}^\infty}[g - g_n]]](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D_%7Bg+%7C+%5C%7B%5Cpi_j%5C%7D_%7Bj%3D1%7D%5E%5Cinfty%7D%5Bg+-+g_n%5D%5D&bg=ffffff&fg=000&s=0&c=20201002)

Theorem 3:
Suppose the requirements of Theorem 1 and 2 are satisfied. Then we have the following:
![\mathbb{E}_{\{\pi_j\}_{j=1}^\infty}[P_{P | \{\pi_j\}_{j=1}^\infty}(|| \mathbb{E}_{g | \{\pi_j\}_{j=1}^\infty}[g-g_n]||_{L_1}] -\mathbb{E}_{P | \{\pi_j\}_{j=1}^\infty}[\mathbb{E}_{g | \{\pi_j\}_{j=1}^\infty}[||g - g_n||_{L_1}]] > t)] \leq \mathbb{E}_{\{\pi_j\}_{j=1}^\infty}[\exp[\frac{-t}{(\sum_{j=n+1}^\infty \pi_j^2) c(K_0)}]]](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D_%7B%5C%7B%5Cpi_j%5C%7D_%7Bj%3D1%7D%5E%5Cinfty%7D%5BP_%7BP+%7C+%5C%7B%5Cpi_j%5C%7D_%7Bj%3D1%7D%5E%5Cinfty%7D%28%7C%7C+%5Cmathbb%7BE%7D_%7Bg+%7C+%5C%7B%5Cpi_j%5C%7D_%7Bj%3D1%7D%5E%5Cinfty%7D%5Bg-g_n%5D%7C%7C_%7BL_1%7D%5D+-%5Cmathbb%7BE%7D_%7BP+%7C+%5C%7B%5Cpi_j%5C%7D_%7Bj%3D1%7D%5E%5Cinfty%7D%5B%5Cmathbb%7BE%7D_%7Bg+%7C+%5C%7B%5Cpi_j%5C%7D_%7Bj%3D1%7D%5E%5Cinfty%7D%5B%7C%7Cg+-+g_n%7C%7C_%7BL_1%7D%5D%5D+%3E+t%29%5D+%5Cleq+%5Cmathbb%7BE%7D_%7B%5C%7B%5Cpi_j%5C%7D_%7Bj%3D1%7D%5E%5Cinfty%7D%5B%5Cexp%5B%5Cfrac%7B-t%7D%7B%28%5Csum_%7Bj%3Dn%2B1%7D%5E%5Cinfty+%5Cpi_j%5E2%29+c%28K_0%29%7D%5D%5D&bg=ffffff&fg=000&s=0&c=20201002)
Proof:
Take the probability expression
, with the term involving 
![\mathbb{E}_{\{\pi_j\}_{j=1}^\infty}[P_{P | \{\pi_j\}_{j=1}^\infty}(|| \mathbb{E}_{g | \{\pi_j\}_{j=1}^\infty}[g-g_n]||_{L_1}] > \mathbb{E}_{P | \{\pi_j\}_{j=1}^\infty}[||\mathbb{E}_{g | \{\pi_j\}_{j=1}^\infty}[g - g_n]||_{L_1}]] + t)]\leq \mathbb{E}_{\{\pi_j\}_{j=1}^\infty}[\exp[\frac{-t^2}{(\sum_{j=n+1}^\infty \pi_j^2) \sigma^2_\mathbf{T}}]](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D_%7B%5C%7B%5Cpi_j%5C%7D_%7Bj%3D1%7D%5E%5Cinfty%7D%5BP_%7BP+%7C+%5C%7B%5Cpi_j%5C%7D_%7Bj%3D1%7D%5E%5Cinfty%7D%28%7C%7C+%5Cmathbb%7BE%7D_%7Bg+%7C+%5C%7B%5Cpi_j%5C%7D_%7Bj%3D1%7D%5E%5Cinfty%7D%5Bg-g_n%5D%7C%7C_%7BL_1%7D%5D+%3E+%5Cmathbb%7BE%7D_%7BP+%7C+%5C%7B%5Cpi_j%5C%7D_%7Bj%3D1%7D%5E%5Cinfty%7D%5B%7C%7C%5Cmathbb%7BE%7D_%7Bg+%7C+%5C%7B%5Cpi_j%5C%7D_%7Bj%3D1%7D%5E%5Cinfty%7D%5Bg+-+g_n%5D%7C%7C_%7BL_1%7D%5D%5D+%2B+t%29%5D%5Cleq+%5Cmathbb%7BE%7D_%7B%5C%7B%5Cpi_j%5C%7D_%7Bj%3D1%7D%5E%5Cinfty%7D%5B%5Cexp%5B%5Cfrac%7B-t%5E2%7D%7B%28%5Csum_%7Bj%3Dn%2B1%7D%5E%5Cinfty+%5Cpi_j%5E2%29+%5Csigma%5E2_%5Cmathbf%7BT%7D%7D%5D&bg=ffffff&fg=000&s=0&c=20201002)
Note that 
![\mathbb{E}_{\{\pi_j\}_{j=1}^\infty}[P_{P | \{\pi_j\}_{j=1}^\infty}(|| \mathbb{E}_{g | \{\pi_j\}_{j=1}^\infty}[g-g_n]||_{L_1}] > \mathbb{E}_{P | \{\pi_j\}_{j=1}^\infty}[||\mathbb{E}_{g | \{\pi_j\}_{j=1}^\infty}[g - g_n]||_{L_1}] + t)]\leq \mathbb{E}_{\{\pi_j\}_{j=1}^\infty}[\exp[\frac{-t^2}{(\sum_{j=n+1}^\infty \pi_j^2) c(K_0)}]](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D_%7B%5C%7B%5Cpi_j%5C%7D_%7Bj%3D1%7D%5E%5Cinfty%7D%5BP_%7BP+%7C+%5C%7B%5Cpi_j%5C%7D_%7Bj%3D1%7D%5E%5Cinfty%7D%28%7C%7C+%5Cmathbb%7BE%7D_%7Bg+%7C+%5C%7B%5Cpi_j%5C%7D_%7Bj%3D1%7D%5E%5Cinfty%7D%5Bg-g_n%5D%7C%7C_%7BL_1%7D%5D+%3E+%5Cmathbb%7BE%7D_%7BP+%7C+%5C%7B%5Cpi_j%5C%7D_%7Bj%3D1%7D%5E%5Cinfty%7D%5B%7C%7C%5Cmathbb%7BE%7D_%7Bg+%7C+%5C%7B%5Cpi_j%5C%7D_%7Bj%3D1%7D%5E%5Cinfty%7D%5Bg+-+g_n%5D%7C%7C_%7BL_1%7D%5D+%2B+t%29%5D%5Cleq+%5Cmathbb%7BE%7D_%7B%5C%7B%5Cpi_j%5C%7D_%7Bj%3D1%7D%5E%5Cinfty%7D%5B%5Cexp%5B%5Cfrac%7B-t%5E2%7D%7B%28%5Csum_%7Bj%3Dn%2B1%7D%5E%5Cinfty+%5Cpi_j%5E2%29+c%28K_0%29%7D%5D&bg=ffffff&fg=000&s=0&c=20201002)
![\mathbb{E}_{\{\pi_j\}_{j=1}^\infty}[P_{P | \{\pi_j\}_{j=1}^\infty}( ||\mathbb{E}_{g | \{\pi_j\}_{j=1}^\infty}[g - g_n]||_{L_1}]]-\mathbb{E}_{P | \{\pi_j\}_{j=1}^\infty}[||\mathbb{E}_{g | \{\pi_j\}_{j=1}^\infty}[g - g_n]||_{L_1}] > t)] \leq \mathbb{E}_{\{\pi_j\}_{j=1}^\infty}[\exp[\frac{-t}{(\sum_{j=n+1}^\infty \pi_j^2) c(K_0)}]]](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D_%7B%5C%7B%5Cpi_j%5C%7D_%7Bj%3D1%7D%5E%5Cinfty%7D%5BP_%7BP+%7C+%5C%7B%5Cpi_j%5C%7D_%7Bj%3D1%7D%5E%5Cinfty%7D%28+%7C%7C%5Cmathbb%7BE%7D_%7Bg+%7C+%5C%7B%5Cpi_j%5C%7D_%7Bj%3D1%7D%5E%5Cinfty%7D%5Bg+-+g_n%5D%7C%7C_%7BL_1%7D%5D%5D-%5Cmathbb%7BE%7D_%7BP+%7C+%5C%7B%5Cpi_j%5C%7D_%7Bj%3D1%7D%5E%5Cinfty%7D%5B%7C%7C%5Cmathbb%7BE%7D_%7Bg+%7C+%5C%7B%5Cpi_j%5C%7D_%7Bj%3D1%7D%5E%5Cinfty%7D%5Bg+-+g_n%5D%7C%7C_%7BL_1%7D%5D+%3E+t%29%5D+%5Cleq+%5Cmathbb%7BE%7D_%7B%5C%7B%5Cpi_j%5C%7D_%7Bj%3D1%7D%5E%5Cinfty%7D%5B%5Cexp%5B%5Cfrac%7B-t%7D%7B%28%5Csum_%7Bj%3Dn%2B1%7D%5E%5Cinfty+%5Cpi_j%5E2%29+c%28K_0%29%7D%5D%5D&bg=ffffff&fg=000&s=0&c=20201002)
Let’s examine this theorem for a second. As 



As we increase the threshold 
This is all intuitive. As the DP has more atoms removing any individual primary atom doesn’t have as much of an influence on the approximation of the truncation to the DP itself. If there are only 3 atoms and you remove two, then you will get a bad truncation error.
Note also that examining a small number of principal atoms ![\mathbb{E}_{P | \{\pi_j\}_{j=1}^\infty}[||\mathbb{E}_{g | \{\pi_j\}_{j=1}^\infty}[g - g_n]||_{L_1}] \rightarrow 0](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D_%7BP+%7C+%5C%7B%5Cpi_j%5C%7D_%7Bj%3D1%7D%5E%5Cinfty%7D%5B%7C%7C%5Cmathbb%7BE%7D_%7Bg+%7C+%5C%7B%5Cpi_j%5C%7D_%7Bj%3D1%7D%5E%5Cinfty%7D%5Bg+-+g_n%5D%7C%7C_%7BL_1%7D%5D+%5Crightarrow+0&bg=ffffff&fg=000&s=0&c=20201002)

![\mathbb{E}_{\{\pi_j\}_{j=1}^\infty}[P_{P | \{\pi_j\}_{j=1}^\infty}( ||\mathbb{E}_{g | \{\pi_j\}_{j=1}^\infty}[g-g_n]||_{L_1}] > t)] \leq \mathbb{E}_{\{\pi_j\}_{j=1}^\infty}[\exp[\frac{-t}{(\sum_{j=n+1}^\infty \pi_j^2) c(K_0)}]]](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D_%7B%5C%7B%5Cpi_j%5C%7D_%7Bj%3D1%7D%5E%5Cinfty%7D%5BP_%7BP+%7C+%5C%7B%5Cpi_j%5C%7D_%7Bj%3D1%7D%5E%5Cinfty%7D%28+%7C%7C%5Cmathbb%7BE%7D_%7Bg+%7C+%5C%7B%5Cpi_j%5C%7D_%7Bj%3D1%7D%5E%5Cinfty%7D%5Bg-g_n%5D%7C%7C_%7BL_1%7D%5D+%3E+t%29%5D+%5Cleq+%5Cmathbb%7BE%7D_%7B%5C%7B%5Cpi_j%5C%7D_%7Bj%3D1%7D%5E%5Cinfty%7D%5B%5Cexp%5B%5Cfrac%7B-t%7D%7B%28%5Csum_%7Bj%3Dn%2B1%7D%5E%5Cinfty+%5Cpi_j%5E2%29+c%28K_0%29%7D%5D%5D&bg=ffffff&fg=000&s=0&c=20201002)
That is, the bound as a function of
Another interesting thing to consider is that the expectation over
![P_{P | \{\pi_j\}_{j=1}^\infty}( ||\mathbb{E}_{g | \{\pi_j\}_{j=1}^\infty}[g-g_n]||_{L_1}] -\mathbb{E}_{P | \{\pi_j\}_{j=1}^\infty}[||\mathbb{E}_{g | \{\pi_j\}_{j=1}^\infty}[g - g_n]||_{L_1}] > t) \leq \exp[\frac{-t}{(\sum_{j=n+1}^\infty \pi_j^2) c(K_0)}]](https://s0.wp.com/latex.php?latex=P_%7BP+%7C+%5C%7B%5Cpi_j%5C%7D_%7Bj%3D1%7D%5E%5Cinfty%7D%28+%7C%7C%5Cmathbb%7BE%7D_%7Bg+%7C+%5C%7B%5Cpi_j%5C%7D_%7Bj%3D1%7D%5E%5Cinfty%7D%5Bg-g_n%5D%7C%7C_%7BL_1%7D%5D+-%5Cmathbb%7BE%7D_%7BP+%7C+%5C%7B%5Cpi_j%5C%7D_%7Bj%3D1%7D%5E%5Cinfty%7D%5B%7C%7C%5Cmathbb%7BE%7D_%7Bg+%7C+%5C%7B%5Cpi_j%5C%7D_%7Bj%3D1%7D%5E%5Cinfty%7D%5Bg+-+g_n%5D%7C%7C_%7BL_1%7D%5D+%3E+t%29+%5Cleq+%5Cexp%5B%5Cfrac%7B-t%7D%7B%28%5Csum_%7Bj%3Dn%2B1%7D%5E%5Cinfty+%5Cpi_j%5E2%29+c%28K_0%29%7D%5D&bg=ffffff&fg=000&s=0&c=20201002)


A final interesting thing to consider is that we don’t have to remove the principal 
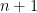

EDITED:
Contraction Rates:
We have that the model is given by:




with 

This gives that the base measure is the finite dimensional 

Let the true random effects law 

The true marginal law of 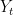



Metrics:
- On the Mixing law
: Wasserstein
over
- On the induced marginal
for

Theorem 4 (Mixing law, Wasserstein):
Assume the true 
![\Theta = \{f: [0,1]^d \rightarrow \mathbb{R} \hspace{2mm} \textrm{s.t.} \hspace{2mm} ||f||_{C^\alpha}< M\}](https://s0.wp.com/latex.php?latex=%5CTheta+%3D+%5C%7Bf%3A+%5B0%2C1%5D%5Ed+%5Crightarrow+%5Cmathbb%7BR%7D+%5Chspace%7B2mm%7D+%5Ctextrm%7Bs.t.%7D+%5Chspace%7B2mm%7D+%7C%7Cf%7C%7C_%7BC%5E%5Calpha%7D%3C+M%5C%7D&bg=ffffff&fg=000&s=0&c=20201002)
![\alpha \in (0,1]](https://s0.wp.com/latex.php?latex=%5Calpha+%5Cin+%280%2C1%5D&bg=ffffff&fg=000&s=0&c=20201002)

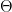



at the (near) minimax nonparametric rate:
Proof:
The relevant background from the notes is Lemma 3, and the testing and KL results in the linked paper that’s available in my publications section.
- The prior mass near the truth in
with nonatomic base measure on a holder ball ( the Lemma 3 style lower bound and packing number appearance): the display involving
shows the DP prior puts strictly positive mass on
- The dependence of the packing/covering number
is explicitly and is the engine behind the
dependence. (Holder balls satisfy
.
- The notes set up the testing and Kullback Leibler Pieces. The
support definition and
Putting these together with the standard master theorem for contraction rates (entropy vs. sample size) yields the rate solving:

Theorem 5 (Contraction of the induced marginal
If the true 




Why parametric?:
With 


Practical Reading of the Rates:
- If your aim is to learn the distribution of the latent spatial fields
(i.e.
, and sample size
.
- If you only care about the marginal law of the observed vector
rate.
Conclusion:
That completes the blog post. I’m going to come back and do some simulations and add some figures so people can better see and understand what I was thinking as I worked on these problems. It’s nice to revisit old work and see it with fresh eyes, and I’m happy it still made somewhat sense to me while looking at it.
Leave a Reply