
(Work in Progress)
It had been a while since I had worked on a technical blog post, so I wanted to get something out there. I have been playing around with a lot of concepts in my head centering on Gaussian processes and using them for Bayesian computation. Most of the time when I write on technical topics I’m working on it as I’m writing (e.g. using the blog post as my scratch pad). I think this serves two purposes: the first is it gives me a framework for working through a problem and an evolving template, and the second is it makes the dialogue surrounding the central themes of the post more narrative in structure.
The problem I was toying around with in my head was something to the effect of having a grid of values which we could pass through the unnormalized posterior, and then fitting a gaussian process to them embedded in a kernel function. At first pass this does nothing really useful, as the unnormalized-kernel-embedded gaussian process is only really fitting values which might be much higher or much lower in absolute value than the true posterior value after normalization. I was curious if we might be able to use some trickery with KL divergences and some functional analysis to figure out a way to normalize the gaussian process to better fit the true posterior.
The uncertainty of the gaussian process would represent the so called uncertainty “around” the true value of the posterior at each particular point, and by incorporating observation uncertainty into the fixed points we can prevent overfitting the unnormalized posterior at these values.
I should note, when I was thinking about doing this I was mostly interested in it as a mathematical curiosity, and as I’m going I’m thinking about ways in which the work could be practically useful.
The first step is to find a grid of values 

Take ![\exp[\circ]](https://s0.wp.com/latex.php?latex=%5Cexp%5B%5Ccirc%5D&bg=ffffff&fg=000&s=0&c=20201002)
![\exp[f(\theta)]](https://s0.wp.com/latex.php?latex=%5Cexp%5Bf%28%5Ctheta%29%5D&bg=ffffff&fg=000&s=0&c=20201002)
![f(\theta) \sim GP(\mu, \exp[-t K(\Theta,\Theta)])](https://s0.wp.com/latex.php?latex=f%28%5Ctheta%29+%5Csim+GP%28%5Cmu%2C+%5Cexp%5B-t+K%28%5CTheta%2C%5CTheta%29%5D%29&bg=ffffff&fg=000&s=0&c=20201002)
This is an Ornstein Ohlenbeck process where the process as a function of time tends towards the mean process around 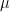


The goal here is to think about 

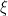

We note that this is a log gaussian process and if we take the log unnormalized values 


Fit these values to obtain ![\exp[f(\theta) - c]](https://s0.wp.com/latex.php?latex=%5Cexp%5Bf%28%5Ctheta%29+-+c%5D+&bg=ffffff&fg=000&s=0&c=20201002)

We then try and normalize this log gaussian process:
![\int_{\theta \in \Theta} \exp[f(\theta) - c] d\theta](https://s0.wp.com/latex.php?latex=%5Cint_%7B%5Ctheta+%5Cin+%5CTheta%7D+%5Cexp%5Bf%28%5Ctheta%29+-+c%5D+d%5Ctheta&bg=ffffff&fg=000&s=0&c=20201002)

I was mainly curious if we could incorporate some type of LogSumExp function with the Riemann integral of this smooth function. E.g. come up with a partition of 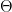


![\int_{\theta \in \Theta} \exp[f(\theta)-c] d\theta = \lim_{n\rightarrow \infty} \sum_{v \in \mathbf{V}_n} |v| \sup_{\theta \in v} \frac{\exp[f(\theta)]}{\log c}](https://s0.wp.com/latex.php?latex=%5Cint_%7B%5Ctheta+%5Cin+%5CTheta%7D+%5Cexp%5Bf%28%5Ctheta%29-c%5D+d%5Ctheta+%3D+%5Clim_%7Bn%5Crightarrow+%5Cinfty%7D+%5Csum_%7Bv+%5Cin+%5Cmathbf%7BV%7D_n%7D+%7Cv%7C+%5Csup_%7B%5Ctheta+%5Cin+v%7D+%5Cfrac%7B%5Cexp%5Bf%28%5Ctheta%29%5D%7D%7B%5Clog+c%7D&bg=ffffff&fg=000&s=0&c=20201002)
with 
This is where the LogSumExp comes in. Note that this function is a smooth approximation to the maximum, and that the following is true:

Placing this function inside the Riemann sum in the limit gives us:
![\lim_{n\rightarrow \infty} \exp[LSE[\log(|v_1|) + \sup_{\theta \in v_1} f(\theta) - c, \dots, \log(|v_n |) + \sup_{\theta \in v_1} f(\theta)]] = \int_{\theta \in \Theta} \frac{\exp[f(\theta)]}{c} d\theta](https://s0.wp.com/latex.php?latex=%5Clim_%7Bn%5Crightarrow+%5Cinfty%7D+%5Cexp%5BLSE%5B%5Clog%28%7Cv_1%7C%29+%2B+%5Csup_%7B%5Ctheta+%5Cin+v_1%7D+f%28%5Ctheta%29+-+c%2C+%5Cdots%2C+%5Clog%28%7Cv_n+%7C%29+%2B+%5Csup_%7B%5Ctheta+%5Cin+v_1%7D+f%28%5Ctheta%29%5D%5D+%3D+%5Cint_%7B%5Ctheta+%5Cin+%5CTheta%7D+%5Cfrac%7B%5Cexp%5Bf%28%5Ctheta%29%5D%7D%7Bc%7D+d%5Ctheta+&bg=ffffff&fg=000&s=0&c=20201002)
This is where some trickery comes in. We know that we’re approximating our posterior with this kernel-embedded Gaussian process, and this is the Riemann integral over these random functions, so we set it equal to 1:
![\frac{1}{log c}\lim_{n\rightarrow \infty} \exp[LSE[\log(|v_1|) + \sup_{\theta \in v_1} f(\theta), \dots, \log(|v_n |) + \sup_{\theta \in v_1} f(\theta)]] = \int_{\theta \in \Theta} \frac{\exp[f(\theta)]}{c} d\theta = 1](https://s0.wp.com/latex.php?latex=%5Cfrac%7B1%7D%7Blog+c%7D%5Clim_%7Bn%5Crightarrow+%5Cinfty%7D+%5Cexp%5BLSE%5B%5Clog%28%7Cv_1%7C%29+%2B+%5Csup_%7B%5Ctheta+%5Cin+v_1%7D+f%28%5Ctheta%29%2C+%5Cdots%2C+%5Clog%28%7Cv_n+%7C%29+%2B+%5Csup_%7B%5Ctheta+%5Cin+v_1%7D+f%28%5Ctheta%29%5D%5D+%3D+%5Cint_%7B%5Ctheta+%5Cin+%5CTheta%7D++%5Cfrac%7B%5Cexp%5Bf%28%5Ctheta%29%5D%7D%7Bc%7D+d%5Ctheta+%3D+1+&bg=ffffff&fg=000&s=0&c=20201002)
Note that if the partition is uniform then the 
![\lim_{n\rightarrow \infty} \exp[LSE[\sup_{\theta \in v_1} f(\theta), \dots, \sup_{\theta \in v_n} f(\theta)]] *|v_n | = \int_{\theta \in \Theta} \exp[f(\theta)] d\theta = \log c](https://s0.wp.com/latex.php?latex=%5Clim_%7Bn%5Crightarrow+%5Cinfty%7D+%5Cexp%5BLSE%5B%5Csup_%7B%5Ctheta+%5Cin+v_1%7D+f%28%5Ctheta%29%2C+%5Cdots%2C+%5Csup_%7B%5Ctheta+%5Cin+v_n%7D+f%28%5Ctheta%29%5D%5D+%2A%7Cv_n+%7C+%3D+%5Cint_%7B%5Ctheta+%5Cin+%5CTheta%7D+%5Cexp%5Bf%28%5Ctheta%29%5D+d%5Ctheta+%3D+%5Clog+c&bg=ffffff&fg=000&s=0&c=20201002)
I’m going to revisit this later when I have some time to read more on extreme value theory, but what I was trying to come up with was a way to get a distribution over marginal likelihoods. There might be different interpretations of this quantity related to model validation and quality depending on the original kernel of the gaussian process (
Using Decision Theory and KL Divergences to Find Optimal Approximation to Posterior:
Note that our original goal was an approximation to the posterior by a log-gaussian random function.
Leave a Reply